How to Think About GPUs
Part 12 of How To Scale Your Model (Part 11: Conclusion | The End)
우리는 Google의 TPU를 사랑하지만, GPU도 훌륭합니다. 이 장에서는 각 칩이 어떻게 작동하고, 서로 어떻게 네트워크로 연결되는지, 그리고 이것이 LLM에 어떤 의미를 갖는지, 특히 TPU와 비교하여 깊이 있게 살펴봅니다. NVIDIA, AMD, Intel 등 다양한 GPU 아키텍처가 있지만 여기서는 NVIDIA GPU에 중점을 둘 것입니다. 이 섹션은 2장과 5장을 기반으로 하므로 먼저 읽어보시는 것을 권장합니다.
번역 안내: 원저자(Jacob Austin)의 허락을 받아 원문을 번역 중입니다.
해당 글의 1인칭은 원문 저자를 지칭합니다.
원문: How to Scale Your Model
번역: 신종훈
What Is a GPU?
현대 ML GPU(예: H100, B200)는 기본적으로 행렬 곱셈에 특화된 다수의 연산 코어(Streaming Multiprocessors 또는 SMs라고 함)가 빠른 메모리 스틱(HBM이라고 함)에 연결된 형태입니다. 다음은 다이어그램입니다:
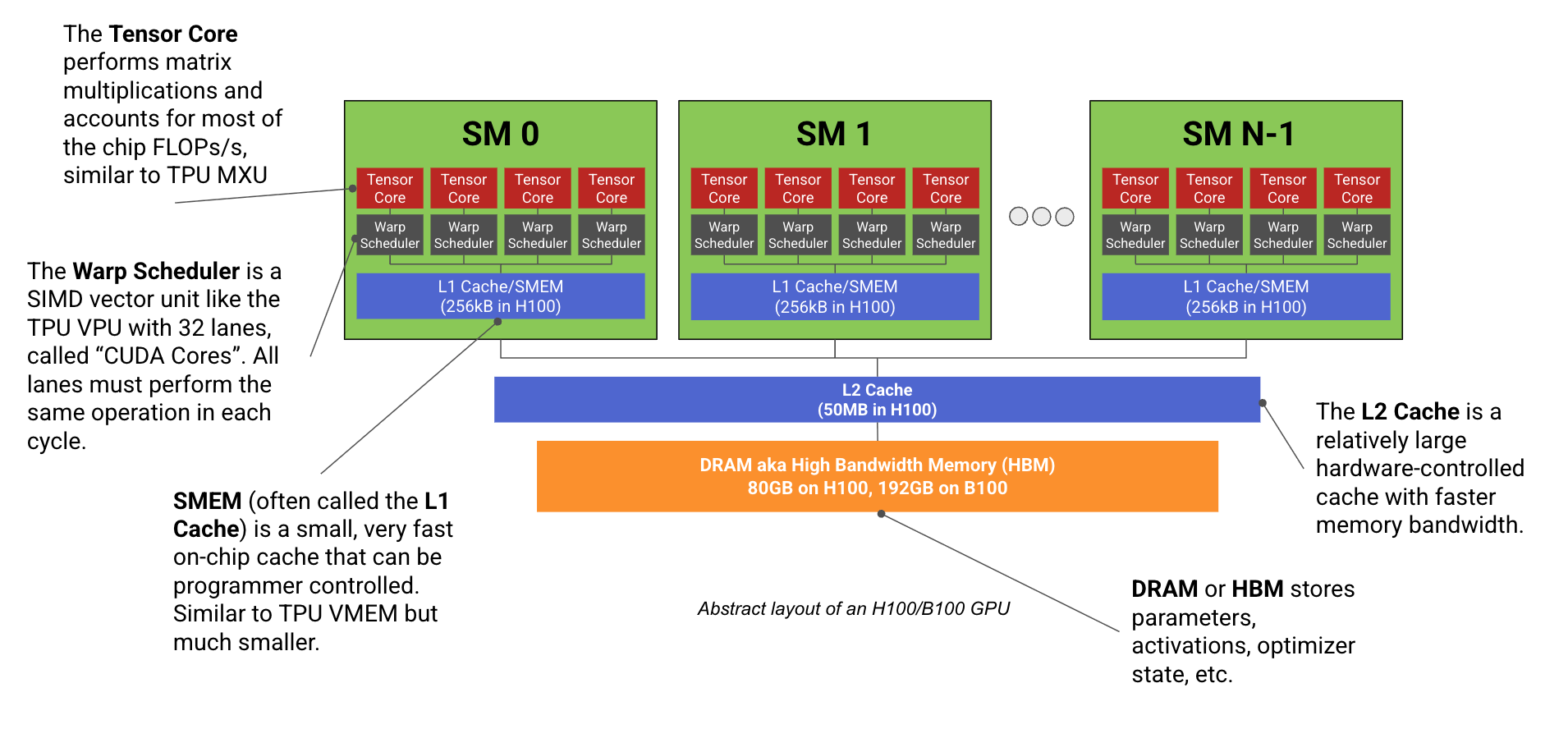
각 SM은 TPU의 Tensor Core와 마찬가지로 전용 행렬 곱셈 코어(불행히도 이것도 Tensor Core라고 부름
H100 SM을 더 자세히 살펴보겠습니다:
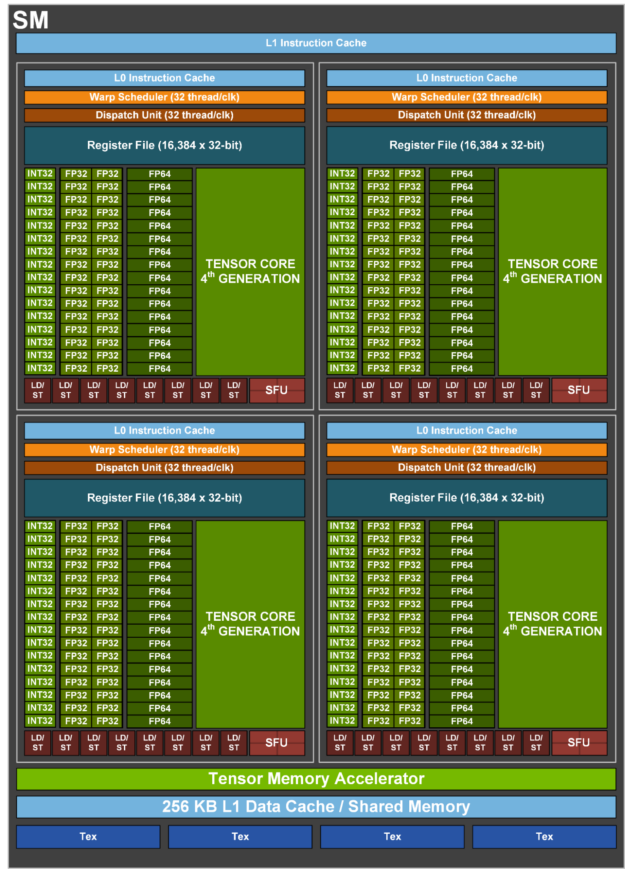
각 SM은 NVIDIA가 SM subpartitions라고 부르는 4개의 동일한 사분면으로 나뉘며, 각 사분면에는 Tensor Core, 16k 32비트 레지스터, 그리고 Warp Scheduler라고 하는 SIMD/SIMT 벡터 산술 유닛이 포함되어 있습니다. Warp Scheduler의 레인(ALU)을 NVIDIA는 CUDA Cores라고 부릅니다. 각 파티션의 핵심 구성 요소는 틀림없이 행렬 곱셈을 수행하고 FLOPs/s의 대부분을 차지하는 Tensor Core이지만, 주목할 만한 유일한 구성 요소는 아닙니다.
-
CUDA Cores: 각 하위 파티션에는 SIMD/SIMT 벡터 산술을 수행하는 CUDA Cores라는 ALU 세트가 포함되어 있습니다. 각 ALU는 일반적으로 사이클당 1개의 산술 op을 수행할 수 있습니다(예: f32.add).
최신 GPU는 사이클당 기술적으로 두 개의 FLOPs를 수행하는 FMA(Fused-Multiply Add) 명령어를 지원하며, NVIDIA는 보고된 사양을 두 배로 늘리기 위해 이 사실을 무자비하게 사용합니다. 각 하위 파티션에는 32개의 fp32 코어(및 더 적은 수의 int32 및 fp64 코어)가 포함되어 있으며, 모두 각 사이클에서 동일한 명령어를 실행합니다. TPU의 VPU와 마찬가지로 CUDA 코어는 ReLU, pointwise 벡터 연산 및 reduction(합계)을 담당합니다.역사적으로 Tensor Core가 도입되기 전에는 CUDA 코어가 GPU의 주요 구성 요소였으며 광선-삼각형 교차 및 셰이딩을 포함한 렌더링에 사용되었습니다. 오늘날의 게임용 GPU에서는 여전히 렌더링 작업의 대부분을 수행하는 반면, TensorCores는 업샘플링(DLSS)에 사용되어 GPU가 더 낮은 해상도(더 적은 픽셀 = 더 적은 작업)에서 렌더링하고 ML을 사용하여 업샘플링할 수 있게 합니다. -
Tensor Core (TC): 각 하위 파티션에는 TPU MXU와 같은 전용 행렬 곱셈 유닛인 자체 Tensor Core가 있습니다. Tensor Core는 GPU FLOPs/s의 대부분을 차지합니다(예: H100의 경우 66 TFLOPs/s의 CUDA 코어에 비해 990 bf16 TC TFLOP/s를 가짐).
- 1.76GHz에서 실행되는 132 SM으로 990 bf16 TFLOPs/s는 각 H100 TC가
7.5e12 / 1.76e9 / 4 ~ 1024bf16 FLOPs/cycle, 대략 8x8x8 matmul을 수행할 수 있음을 의미합니다.NVIDIA는 TC 하드웨어 세부 정보를 많이 공유하지 않으므로 이것은 확실한 사실이라기보다는 추측에 가깝습니다. 확실히 TC가 어떻게 구현되는지에 대해서는 말해주지 않습니다. V100이 256 FLOPs/TC/cycle을 수행할 수 있다는 것을 알고 있습니다. A100은 512, H100은 1024를 수행할 수 있으며, B200 세부 정보는 게시되지 않았지만 `2250e12 / (148 * 4 * 1.86e9)`가 약 2048이므로 약 2048 FLOPs/TC/cycle일 가능성이 높습니다. 여기에서 더 많은 세부 정보가 확인되었습니다. - TPU와 마찬가지로 GPU는 더 높은 처리량으로 더 낮은 정밀도의 matmul을 수행할 수 있습니다(예: H100은 fp16 대비 2배의 fp8 FLOPs/s를 가짐). 저정밀도 훈련이나 서빙은 훨씬 빠를 수 있습니다.
- Volta 이후의 각 GPU 세대는 이전 세대에 비해 TC 크기를 늘렸습니다(이에 대한 좋은 기사). B200에서는 TC가 너무 커져 입력을 더 이상 SMEM에 맞출 수 없게 되었으므로 B200은 TMEM이라는 새로운 메모리 공간을 도입했습니다.
Ampere에서는 Tensor Core가 단일 워프에서 공급될 수 있었지만 Hopper에서는 전체 SM(warpgroup)이 필요하고 Blackwell에서는 2개의 SM에서 공급됩니다. Blackwell에서 matmul이 너무 커져 인수(특히 누산기)가 더 이상 레지스터 메모리/SMEM에 맞지 않으므로 Blackwell은 이를 설명하기 위해 TMEM을 추가합니다.
- 1.76GHz에서 실행되는 132 SM으로 990 bf16 TFLOPs/s는 각 H100 TC가
CUDA 코어는 TPU의 VPU보다 유연합니다: GPU CUDA 코어(V100 이후)는 TPU의 SIMD(Single Instruction Multiple Data) 모델과 비교하여 SIMT(Single Instruction Multiple Threads) 프로그래밍 모델이라고 불리는 것을 사용합니다. TPU VPU의 ALU와 마찬가지로 하위 파티션 내의 CUDA 코어는 각 사이클에서 동일한 연산을 수행해야 합니다(예: 한 코어가 두 float를 더하면 하위 파티션의 다른 모든 CUDA 코어도 그렇게 해야 함). 그러나 VPU와 달리 각 CUDA 코어(또는 CUDA 프로그래밍 모델의 “스레드”)는 자체 명령어 포인터를 가지며 독립적으로 프로그래밍_될 수 있습니다. 동일한 워프의 두 스레드가 다른 연산을 수행하도록 지시받으면 사실상 _두 연산을 모두 수행하고 분기된 연산을 수행할 필요가 없는 코어를 마스킹합니다.

이것은 스레드 수준에서 유연한 프로그래밍을 가능하게 하지만, 워프가 너무 자주 분기되면 성능이 조용히 저하되는 비용이 발생합니다. 스레드는 또한 액세스할 수 있는 메모리에서 더 유연할 수 있습니다. VPU는 연속적인 메모리 블록에서만 작동할 수 있지만, CUDA 코어는 공유 레지스터의 개별 float에 액세스하고 스레드별 상태를 유지할 수 있습니다.
CUDA 코어 스케줄링도 더 유연합니다: SM은 동시에 많은 프로그램(warps)을 “스케줄링”할 수 있다는 점에서 멀티 스레드 CPU처럼 실행됩니다(SM당 최대 64개). 하지만 각 _Warp Scheduler_는 각 클럭 사이클에서 단일 프로그램만 실행합니다.
Memory
연산 유닛 외에도 GPU에는 HBM(주 GPU 메모리)을 시작으로 더 작은 일련의 캐시(L2, L1/SMEM, TMEM, 레지스터 메모리)로 이어지는 메모리 계층 구조가 있습니다.
- Registers: 각 하위 파티션에는 H100/B200에서 CUDA 코어가 액세스할 수 있는 16,384개의 32비트 워드를 포함하는 자체 레지스터 파일이 있습니다(SM당
4 * 16384 * 4 = 256kiB).- 각 CUDA 코어는 한 번에 최대 256개의 레지스터에만 액세스할 수 있으므로, SM당 최대 64개의 “resident warps”를 스케줄링할 수 있지만 각 스레드가 256개의 레지스터를 사용하는 경우 한 번에 8개(
256 * 1024 / (4 * 32 * 256))만 맞출 수 있습니다.
- 각 CUDA 코어는 한 번에 최대 256개의 레지스터에만 액세스할 수 있으므로, SM당 최대 64개의 “resident warps”를 스케줄링할 수 있지만 각 스레드가 256개의 레지스터를 사용하는 경우 한 번에 8개(
-
SMEM (L1 Cache): 각 SM에는 SMEM이라는 자체 256kB 온칩 캐시가 있으며, 이는 프로그래머가 “shared memory”로 제어하거나 하드웨어가 온칩 캐시로 사용할 수 있습니다. SMEM은 활성화 및 TC matmul에 대한 입력을 저장하는 데 사용됩니다.
- L2 Cache: 모든 SM은 주 메모리 액세스를 줄이기 위해 사용되는 비교적 큰 ~50MB L2 캐시를 공유
엄밀히 말하면 L2 캐시는 둘로 나뉘어 있어 SM의 절반이 H100에서 각각 25MB에 액세스할 수 있습니다. 두 절반을 연결하는 링크가 있지만 대역폭이 낮습니다. 합니다.- 이것은 TPU의 VMEM과 크기가 비슷하지만 훨씬 느리고 프로그래머가 제어하지 않습니다. 이로 인해 프로그래머가 L2 캐시가 잘 사용되도록 메모리 액세스 패턴을 수정해야 하는 약간의 “원격 작용(spooky action at a distance)”이 발생합니다.
L2 캐시가 모든 SM에 공유된다는 사실은 원칙적으로 독립적인 유닛임에도 불구하고 프로그래머가 SM을 꽤 조정된 방식으로 실행하도록 사실상 강요합니다. - NVIDIA는 칩의 L2 대역폭을 게시하지 않지만 약 5.5TB/s로 측정되었습니다. 따라서 대략 HBM 대역폭의 1.6배이지만 전이중(full-duplex)이므로 유효 양방향 대역폭은 3배에 가깝습니다. 이에 비해 TPU의 VMEM은 2배 더 크고 대역폭도 훨씬 높습니다(약 40TB/s).
- 이것은 TPU의 VMEM과 크기가 비슷하지만 훨씬 느리고 프로그래머가 제어하지 않습니다. 이로 인해 프로그래머가 L2 캐시가 잘 사용되도록 메모리 액세스 패턴을 수정해야 하는 약간의 “원격 작용(spooky action at a distance)”이 발생합니다.
- HBM: 주 GPU 메모리로 모델 가중치, 그라디언트, 활성화 등을 저장하는 데 사용됩니다.
- HBM 크기는 Volta의 32GB에서 Blackwell(B200)의 192GB로 많이 증가했습니다.
- HBM에서 CUDA Tensor Core로의 대역폭을 HBM 대역폭 또는 메모리 대역폭이라고 하며 H100에서는 약 3.35TB/s, B200에서는 9TB/s입니다.
Summary of GPU specs
다음은 최신 모델에 대한 GPU 사양 요약입니다. SM 수, 클럭 속도 및 FLOPs는 주어진 GPU의 변형마다 다소 다릅니다. 메모리 용량 수치는 다음과 같습니다:
| GPU | Generation | Clock Speed | SMs/chip | SMEM capacity/SM | L2 capacity/chip | HBM capacity/chip |
|---|---|---|---|---|---|---|
| V100 | Volta | 1.25GHz/1.38HGz | 80 | 96kB | 6MB | 32GB |
| A100 | Ampere | 1.10GHz/1.41GHz | 108 | 192kB | 40MB | 80GB |
| H100 | Hopper | 1.59GHz/1.98GHz | 132 | 256kB | 50MB | 80GB |
| H200 | Hopper | 1.59GHz/1.98GHz | 132 | 256kB | 50MB | 141GB |
| B200 | Blackwell | ? | 148 | 256kB | 126MB | 192GB |
모든 세대에는 SM당 256kB의 레지스터 메모리가 있습니다. Blackwell은 SM당 256kB의 TMEM도 추가합니다. 다음은 각 칩에 대한 FLOPs 및 대역폭 수치입니다:
| GPU | Generation | HBM BW/chip | FLOPs/s/chip (bf16/fp16) | FLOPs/s/chip (fp8/int8) | FLOPs/s/chip (fp4) |
|---|---|---|---|---|---|
| V100 | Volta | 9.0e11 | — | — | — |
| A100 | Ampere | 2.0e12 | 3.1e14 | 6.2e14 | — |
| H100 | Hopper | 3.4e12 | 9.9e14 | 2.0e15 | — |
| H200 | Hopper | 4.8e12 | 9.9e14 | 2.0e15 | — |
| B200 | Blackwell | 8.0e12 | 2.3e15 | 4.5e15 | 9.0e15 |
대량 생산되지 않았기 때문에 B100은 제외합니다.
다음은 GPU와 TPU 구성 요소를 비교한 유용한 요약표입니다:
| GPU | TPU | What is it? |
|---|---|---|
| Streaming Multiprocessor (SM) | Tensor Core | 다른 유닛을 포함하는 코어 “셀” |
| Warp Scheduler | VPU | SIMD 벡터 산술 유닛 |
| CUDA Core | VPU ALU | SIMD ALU |
| SMEM (L1 Cache) | VMEM | 빠른 온칩 캐시 메모리 |
| Tensor Core | MXU | 행렬 곱셈 유닛 |
| HBM (aka GMEM) | HBM | 고대역폭 대용량 메모리 |
GPUs vs. TPUs at the chip level
GPU는 비디오 게임 렌더링으로 시작했지만, 2010년대에 딥러닝이 부상한 이후로 점점 더 전용 행렬 곱셈 기계, 즉 TPU와 비슷하게 작동하기 시작했습니다.
GPU는 더 모듈식입니다. TPU에는 1-2개의 큰 Tensor Core가 있는 반면, GPU에는 수백 개의 작은 SM이 있습니다. 마찬가지로 각 Tensor Core에는 각각 1024개의 ALU가 있는 4개의 큰 VPU가 있는 반면, GPU에는 H100에 132 * 4 = 528개의 작은 독립 SIMD 유닛이 있습니다. 다음은 이 점을 강조하는 GPU 대 TPU의 1:1 비교입니다:
| GPU | TPU | H100 # | TPU v5p # |
|---|---|---|---|
| SM (streaming multiprocessor) | Tensor Core | 132 | 2 |
| Warp Scheduler | VPU | 528 | 8 |
| SMEM (L1 cache) | VMEM | 32MB | 128MB |
| Registers | Vector Registers (VRegs) | 32MB | 256kB |
| Tensor Core | MXU | 528 | 8 |
모듈성의 이러한 차이는 한편으로는 TPU를 구축하기 훨씬 저렴하고 이해하기 쉽게 만들지만, 다른 한편으로는 컴파일러가 올바른 일을 하도록 더 많은 부담을 줍니다. TPU는 단일 제어 스레드를 가지며 벡터화된 VPU 전체 명령어만 지원하기 때문에 컴파일러는 정지(stalls)를 피하기 위해 모든 메모리 로드와 MXU/VPU 작업을 수동으로 파이프라인해야 합니다. GPU 프로그래머는 각각 완전히 독립적인 SM에서 실행되는 수십 개의 다른 커널을 시작할 수 있습니다. 반면에 이러한 커널은 L2 캐시를 쓰레싱하거나 메모리 로드를 병합(coalesce)하지 못해 끔찍한 성능을 얻을 수 있습니다. 하드웨어가 런타임의 많은 부분을 제어하기 때문에 백그라운드에서 무슨 일이 일어나고 있는지 추론하기 어렵습니다. 결과적으로 TPU는 더 적은 노력으로 피크 루프라인 성능에 더 가까워질 수 있는 경우가 많습니다.
역사적으로 개별 GPU는 비교 가능한 TPU보다 더 강력하고(더 비쌉니다): 단일 H200은 TPU v5p의 2배에 가까운 FLOPs/s와 1.5배의 HBM을 가집니다. 동시에 Google Cloud의 정가는 TPU v5p의 $4/시간에 비해 H200은 약 $10/시간입니다. TPU는 일반적으로 GPU보다 여러 칩을 함께 네트워킹하는 데 더 많이 의존합니다.
TPU는 훨씬 더 많은 빠른 캐시 메모리를 가지고 있습니다. TPU는 또한 GPU가 가진 SMEM(+TMEM)보다 훨씬 더 많은 VMEM을 가지고 있으며, 이 메모리는 가중치와 활성화를 매우 빠르게 로드하고 사용할 수 있는 방식으로 저장하는 데 사용될 수 있습니다. 이를 통해 모델 가중치를 VMEM에 일관되게 저장하거나 미리 가져올 수 있다면 LLM 추론에 더 빠를 수 있습니다.
Quiz 1: GPU hardware
다음은 위의 내용 중 일부를 테스트하는 몇 가지 문제입니다. 정답이 제공되지만, 펜과 종이를 들고 정답을 보기 전에 질문에 답해 보는 것이 좋습니다.
Question 1 [CUDA cores]: H100에는 몇 개의 fp32 CUDA 코어(ALU)가 있나요? B200은요? 이것은 TPU v5p의 독립 ALU 수와 어떻게 비교되나요?
답을 보려면 여기를 클릭하세요.
Answer: H100에는 각각 32개의 fp32 CUDA 코어를 포함하는 4개의 하위 파티션이 있는 132개의 SM이 있으므로 132 * 4 * 32 = 16896 CUDA 코어입니다. B200은 148개의 SM을 가지고 있으므로 총 18944개입니다. TPU v5p에는 2개의 TensorCore(보통 Megacore를 통해 연결됨)가 있으며, 각각 (8, 128) 레인과 레인당 4개의 독립 ALU가 있는 VPU를 가지고 있으므로 2 * 4 * 8 * 128 = 8192 ALU입니다. 이는 대략 같은 주파수에서 실행되는 H100의 벡터 레인 수의 절반입니다.
Question 2 [Vector FLOPs calculation]: 단일 H100에는 132개의 SM이 있으며 1.59GHz(최대 1.98GHz 부스트)의 클럭 속도로 실행됩니다. ALU당 사이클당 하나의 벡터 op을 수행할 수 있다고 가정합니다. 초당 얼마나 많은 벡터 fp32 FLOPs를 수행할 수 있나요? 부스트 시에는요? matmul FLOPs와 어떻게 비교되나요?
답을 보려면 여기를 클릭하세요.
Answer: 132 * 4 * 32 * 1.59e9 = 26.9TFLOPs/s입니다. 부스트 시 33.5 TFLOPs/s입니다. 이는 사양 시트에 보고된 것의 절반인데, 기술적으로 한 사이클에 FMA(fused-multiply-add)를 수행할 수 있어 두 개의 FLOPs로 계산되지만 대부분의 경우 유용하지 않기 때문입니다. 990 bfloat16 matmul TFLOPs/s를 수행할 수 있으므로 FMA를 무시하면 Tensor Core는 약 30배 더 많은 FLOPs/s를 수행합니다.
Question 3 [GPU matmul intensity]: H100에서 피크 fp16 matmul intensity는 얼마인가요? B200은요? fp8은 어떤가요? intensity란 matmul FLOPs/s 대 메모리 대역폭의 비율을 의미합니다.
답을 보려면 여기를 클릭하세요.
Answer: H100의 경우 피크 990e12 fp16 FLOPs와 3.35e12 bytes / s의 대역폭을 가집니다. 따라서 임계 intensity는 990e12 / 3.35e12 = 295로, TPU의 240과 상당히 비슷합니다. B200의 경우 2250e12 / 8e12 = 281로 매우 비슷합니다. 이는 TPU와 마찬가지로 matmul에서 compute-bound가 되려면 약 280의 배치 크기가 필요하다는 것을 의미합니다.
H100과 B200 모두 정확히 2배의 fp8 FLOPs/s를 가지므로 피크 intensity도 각각 590과 562로 두 배가 되지만, 가중치도 fp8로 로드될 가능성이 높다는 사실을 고려하면 어떤 면에서는 일정하게 유지됩니다.
Question 4 [Matmul runtime]: 질문 3의 답을 사용하여 단일 B200에서 fp16[64, 4096] * fp16[4096, 8192] matmul이 얼마나 걸릴 것으로 예상합니까? fp16[512, 4096] * fp16[4096, 8192]는 어떨까요?
답을 보려면 여기를 클릭하세요.
위에서 우리는 배치 크기 281 토큰 미만에서 통신 병목이 발생할 것임을 알고 있습니다. 따라서 첫 번째는 순수하게 대역폭 제한입니다. 8e12 bytes/s 대역폭으로 $2BD + 2DF + 2BF$ 바이트 (2*64*4096 + 2*4096*8192 + 2*64*8192=69e6)를 읽거나 쓰므로 약 69e6 / 8e12 = 8.6us가 걸릴 것입니다. 실제로는 전체 대역폭의 일부만 얻을 가능성이 높으므로 10-12us에 더 가까울 수 있습니다. 배치 크기를 늘리면 완전히 compute-bound이므로 T=2*512*4096*8192/2.3e15=15us를 예상합니다. 다시 전체 FLOPs의 일부만 예상하므로 20us에 더 가까운 것을 볼 수 있습니다.
Question 5 [L1 cache capacity]: H100의 총 L1/SMEM 용량은 얼마인가요? 레지스터 메모리는요? 이것은 TPU VMEM 용량과 어떻게 비교되나요?
답을 보려면 여기를 클릭하세요.
Answer: SM당 256kB SMEM과 256kB 레지스터 메모리가 있으므로 각각 약 33MB (132 * 256kB)입니다. 합치면 총 약 66MB가 됩니다. 이는 최신 TPU VMEM의 120MB의 약 절반이지만, TPU는 총 레지스터 메모리가 256kB에 불과합니다! TPU VMEM 지연 시간은 SMEM 지연 시간보다 낮으며, 이는 TPU에서 레지스터 메모리가 그렇게 중요하지 않은 한 가지 이유입니다(VMEM으로의 spill과 fill이 저렴함).
Question 6 [Calculating B200 clock frequency]: NVIDIA는 여기에서 B200이 80TFLOPs/s의 벡터 fp32 컴퓨팅을 수행할 수 있다고 보고합니다. 각 CUDA 코어가 FMA(fused multiply add) op에서 사이클당 2 FLOPs를 수행할 수 있다는 점을 감안할 때 피크 클럭 사이클을 추정하세요.
답을 보려면 여기를 클릭하세요.
Answer: 148 * 4 * 32 = 18944 CUDA 코어가 있다는 것을 알고 있으므로 18944 * 2 = 37888 FLOPs / cycle을 수행할 수 있습니다. 따라서 80e12 / 37888 = 2.1GHz로, 높지만 합리적인 피크 클럭 속도입니다. B200은 일반적으로 수랭식이므로 더 높은 클럭 사이클이 더 합리적입니다.
Question 7 [Estimating H100 add runtime]: 위의 수치를 사용하여 단일 H100에서 두 fp32[N] 벡터를 더하는 데 걸리는 시간을 계산하세요. $T_\text{math}$와 $T_\text{comms}$를 모두 계산하세요. 이 연산의 arithmetic intensity는 얼마인가요? 액세스 권한을 얻을 수 있다면 PyTorch나 JAX에서도 N = 1024 및 N=1024 * 1024 * 1024에 대해 이 연산을 실행해 보세요. 어떻게 비교되나요?
답을 보려면 여기를 클릭하세요.
Answer: 첫째, 두 fp32[N] 벡터를 더하는 것은 N FLOPs를 수행하고 4 * N * 2 바이트를 로드하고 4 * N 바이트를 다시 써야 하므로 총 3 * 4 * N = 12N입니다. 비율을 계산하면 total FLOPs / total bytes = N / 12N = 1 / 12이며, 이는 꽤 형편없습니다.
위에서 계산했듯이 FMA를 무시하고 대략 33.5 TFLOPs/s 부스트를 수행할 수 있습니다. 이는 모든 CUDA 코어가 사용되는 경우에만 해당됩니다. N = 1024의 경우 최대 1024개의 CUDA 코어 또는 8개의 SM만 사용할 수 있으므로 더 오래 걸릴 것입니다(compute-bound라고 가정할 때 대략 16배 더 김). 또한 3.35e12 bytes/s의 메모리 대역폭이 있습니다. 따라서 피크 하드웨어 intensity는 33.5e12 / 3.35e12 = 10입니다.
N = 65,536의 경우 약 0.23us입니다. 실제로 JAX에서 약 1.5us의 런타임을 보는데, 여기서 우리는 매우 latency bound일 것으로 예상하므로 괜찮습니다. N = 1024 * 1024 * 1024의 경우 약 3.84ms의 루프라인이 있고 4.1ms를 보는데, 이는 좋습니다!
Networking
네트워킹은 GPU와 TPU가 가장 많이 다른 영역 중 하나입니다. 보시다시피 TPU는 2D 또는 3D 토러스로 연결되어 있으며 각 TPU는 이웃에만 연결됩니다. 즉, 두 TPU 간에 메시지를 보내려면 개입하는 모든 TPU를 통과해야 하며, 메시를 통한 균일한 통신 패턴만 사용하도록 강요합니다. 어떤 면에서는 불편하지만, 이는 TPU당 링크 수가 일정하고 대역폭 손실 없이 임의로 큰 TPU “pod”로 확장할 수 있음을 의미합니다.
반면 GPU는 더 전통적인 계층적 트리 기반 스위칭 네트워크를 사용합니다. 노드라고 하는 8개의 GPU 세트(GB200의 경우 최대 72개

At the node level
GPU 노드는 일반적으로 8개의 GPU(GB200의 경우 최대 72개)로 구성된 작은 유닛으로, all-to-all, 전체 대역폭, 저지연 NVLink 상호 연결로 연결됩니다.5 + 4 + 4 + 5 링크 패턴으로 연결된 GPU가 있는 노드당 4개의 NVSwitch가 있습니다:

Hopper 세대(NVLink 4.0)의 경우 각 NVLink 링크는 25GB/s의 전이중18 * 25=450GB/s의 전이중 대역폭을 제공합니다. 거대한 NVSwitch에는 최대 64개의 NVLink 포트가 있어 4개의 스위치가 있는 8xH100 노드는 최대 64 * 25e9 * 4=6.4TB/s의 대역폭을 처리할 수 있습니다. 다음은 GPU 세대에 따라 이러한 숫자가 어떻게 변경되었는지 보여주는 개요입니다:
| NVLink Gen | NVSwitch Gen | GPU Generation | NVLink Bandwidth (GB/s, full-duplex) | NVLink Ports / GPU | Node GPU to GPU bandwidth (GB/s full-duplex) | Node size (NVLink domain) | NVSwitches per node |
|---|---|---|---|---|---|---|---|
| 3.0 | 2.0 | Ampere | 25 | 12 | 300 | 8 | 6 |
| 4.0 | 3.0 | Hopper | 25 | 18 | 450 | 8 | 4 |
| 5.0 | 4.0 | Blackwell | 50 | 18 | 900 | 8/72 | 2/18 |
Blackwell (B200)에는 8개의 GPU 노드가 있습니다. GB200NVL72는 72개 GPU의 더 큰 NVLink 도메인을 지원합니다. 8개 및 72개 GPU 시스템에 대한 세부 정보를 보여줍니다.
Quiz 2: GPU nodes
다음은 네트워킹에 대한 몇 가지 Q/A 문제입니다. 실제 통신 패턴을 통해 작업하도록 만들기 때문에 이것들이 특히 유용하다고 생각합니다.
Question 1 [Total bandwidth for H100 node]: 4개의 스위치가 있는 8xH100 노드에서 노드당 총 대역폭은 얼마입니까? 힌트: NVLink와 NVSwitch 대역폭을 모두 고려하세요.
답을 보려면 여기를 클릭하세요.
Answer: Gen4 4xNVSwitch가 있으며, 각각 64 * 25e9=1.6TB/s의 단방향 대역폭을 가집니다. 이는 스위치 수준에서 4 * 1.6e12=6.4e12 대역폭을 제공합니다. 그러나 각 GPU는 450GB/s의 단방향 대역폭만 처리할 수 있으므로 최대 450e9 * 8 = 3.6TB/s 대역폭을 가집니다. 이것이 더 작으므로 피크 대역폭은 3.6TB/s입니다.
Question 2 [Bisection bandwidth]: 이등분(Bisection) 대역폭은 네트워크의 임의의 짝수 파티션 간에 사용 가능한 가장 작은 대역폭으로 정의됩니다. 다시 말해, 네트워크를 두 개의 동일한 절반으로 나누면 두 절반 사이를 얼마나 많은 대역폭이 교차할까요? 8x H100 노드의 이등분 대역폭을 계산할 수 있나요? 힌트: 이등분 대역폭은 일반적으로 양방향 흐름을 포함합니다.
답을 보려면 여기를 클릭하세요.
Answer: 모든 짝수 파티션은 각 절반에 4개의 GPU를 가지며, 각 GPU는 다른 절반으로 4 * 450GB/s를 송신할 수 있습니다. 양방향 흐름을 취하면 8 * 450GB/s 바이트가 파티션을 교차하거나 3.6TB/s의 이등분 대역폭을 제공합니다. 이것이 NVIDIA가 예: 여기에서 보고하는 것입니다.
Question 3 [AllGather cost]: B 바이트의 배열이 주어지면 (처리량 제한) AllGather는 8xH100 노드에서 얼마나 걸릴까요? D=4096, F=65,536인 bf16[DX, F]에 대해 계산해 보세요. 이 질문에 답하기 전에 TPU collectives 섹션을 읽어볼 가치가 있습니다. 여기서 이것을 생각해 보겠지만 다음에는 collectives에 대해 훨씬 더 많이 이야기할 것입니다.
답을 보려면 여기를 클릭하세요.
Answer: 각 GPU는 450GB/s를 송신할 수 있고, 각 GPU는 $B / N$ 바이트를 가집니다 (여기서 N=8, 노드 크기). 각 노드가 $N - 1$개의 다른 노드 각각에 차례로 바이트를 보낸다고 상상할 수 있으며, 총 (N - 1) 턴이 발생하며 각각 $T_\text{comms} = (B / (N * W_\text{unidirectional}))$ 또는 $T_\text{comms} = (N - 1) * B / (N * W_\text{unidirectional})$입니다. 이것은 대략 $B / (N * W_\text{uni})$ 또는 $B / \text{3.6e12}$, 즉 이등분 대역폭입니다.
주어진 배열의 경우 B=4096 * 65536 * 2=512MB이므로 총 시간은 536e6 * (8 - 1) / 3.6e12 = 1.04ms입니다. 이것은 latency-bound일 수 있으므로 실제로는 이보다 더 오래 걸릴 수 있습니다(실제로는 약 1.5ms가 걸림).
Beyond the node level
노드 수준을 넘어서면 GPU 네트워크의 토폴로지는 덜 표준화되어 있습니다. NVIDIA는 InfiniBand를 사용하여 단일 노드보다 더 큰 GPU 세트를 연결하는 참조 DGX SuperPod 아키텍처를 게시하지만 고객과 데이터 센터 제공자는 필요에 따라 이를 자유롭게 사용자 정의할 수 있습니다.
다음은 참조 1024 GPU H100 시스템에 대한 다이어그램으로, 맨 아래 행의 각 상자는 8개의 GPU, 8개의 400Gbps CX7 NIC(GPU당 하나), 4개의 NVSwitch가 있는 단일 8xH100 노드입니다.

Scalable Units: 32개 노드의 각 세트를 “Scalable Unit”(또는 SU)이라고 하며, 8개의 leaf InfiniBand 스위치 단일 세트 아래에 있습니다. 이 SU에는 노드당 4개의 NVSwitch와 8개의 Infiniband leaf 스위치가 있는 256개의 GPU가 있습니다. 표시된 모든 케이블은 InfiniBand NDR(50GB/s 전이중)이며 64포트 NDR IB 스위치(포트당 50GB/s)가 있습니다. IB 스위치는 NVSwitch(400Gbps 링크가 있는 64포트) 대역폭의 2배를 가집니다.
SuperPod: 전체 SuperPod는 16개의 최상위 “spine” IB 스위치와 4개의 이러한 SU를 연결하여 1024개의 GPU에 512개의 노드 수준 NVSwitch, 32개의 leaf IB 스위치, 16개의 spine IB 스위치를 제공하여 총 512 + 32 + 16 = 560개의 스위치를 제공합니다. Leaf 스위치는 32개 노드 세트로 노드에 연결되므로 256개의 GPU 세트에는 8개의 leaf 스위치가 있습니다. 모든 leaf 스위치는 모든 spine 스위치에 연결됩니다.
대역폭은 얼마나 될까요? InfiniBand 네트워크(“스케일 아웃 네트워크”라고 함)의 전체 토폴로지는 fat tree이며, 케이블과 스위치는 노드 수준 이상에서 완전한 이등분 대역폭(여기서는 400GB/s)을 보장합니다. 즉, 노드를 절반으로 나누면 각 노드는 동시에 다른 파티션의 노드로 400GB/s를 송신할 수 있습니다. 더 중요한 점은 스케일 아웃 네트워크에서 대략 일정한 AllReduce 대역폭을 가져야 한다는 것을 의미합니다! 이런 방식으로 구현되지 않을 수도 있지만, 모든 노드를 포함하는 링을 구성할 수 있으므로 스케일 아웃 네트워크의 임의의 많은 노드에 대해 링 축소를 수행하는 것을 상상할 수 있습니다.
| Level | GPUs | Switches per Unit | Switch Type | Bandwidth per Unit (TB/s, full-duplex) | GPU-to-GPU Bandwidth (GB/s, full-duplex) | Fat Tree Bandwidth (GB/s, full-duplex) |
|---|---|---|---|---|---|---|
| Node | 8 | 4 | NVL | 3.6 | 450 | 450 |
| Leaf | 256 | 8 | IB | 12.8 | 50 | 400 |
| Spine | 1024 | 16 | IB | 51.2 | 50 | 400 |
이에 비해 TPU v5p는 링크당 약 90GB/s 송신 대역폭, 즉 3D 토러스의 모든 축을 따라 540GB/s 송신을 가집니다. 이것은 포인트 투 포인트가 아니므로 제한적이고 균일한 통신 패턴에만 사용할 수 있지만, 임의로 큰 토폴로지(적어도 최대 8960 TPU)로 확장할 수 있는 훨씬 더 높은 TPU 대 TPU 대역폭을 제공합니다.
GPU 스위칭 패브릭은 이론적으로 추가 지연 시간과 값비싼 네트워크 스위치 비용을 감수하고 추가 스위치나 간접 계층을 추가하여 임의의 크기로 확장할 수 있습니다.
Takeaway: H100 노드 내에서는 각 GPU에서 450GB/s의 전체 fat tree 대역폭을 갖는 반면, 노드를 넘어서는 노드 대 노드 400GB/s로 떨어집니다. 이것은 통신 기본 요소에 중요하게 작용할 것입니다.
GB200 NVL72s: NVIDIA는 최근 전체 900GB/s의 GPU 대 GPU 대역폭을 가진 단일 NVLink 도메인에 72개의 GPU를 결합한 새로운 GB200 NVL72 GPU 클러스터를 생산하기 시작했습니다. 이러한 도메인은 비례적으로 더 높은(9배) IB fat tree 대역폭을 가진 더 큰 SuperPod로 연결될 수 있습니다. 다음은 해당 토폴로지의 다이어그램입니다:

단일 노드(위의 주황색 선)의 송신 대역폭을 계산하면 leaf 수준까지 4 * 18 * 400 / 8 = 3.6TB/s의 대역폭을 가지며, 이는 H100보다 9배 더 많습니다(노드에 9배 더 많은 GPU가 포함된 것처럼). 이는 중요한 노드 송신 대역폭이 훨씬, 훨씬 높으며 노드 간 collective 대역폭이 실제로 노드 내보다 낮을 수 있음을 의미합니다. 자세한 논의는 Appendix A를 참조하세요.
| Node Type | GPUs per node | GPU egress bandwidth | Node egress bandwidth |
|---|---|---|---|
| H100 | 8 | 450e9 | 400e9 |
| B200 | 8 | 900e9 | 400e9 |
| GB200 NVL72 | 72 | 900e9 | 3600e9 |
Takeaway: GB200 NVL72 SuperPods는 노드 크기와 주어진 노드의 송신 대역폭을 획기적으로 증가시켜 루프라인을 크게 변경합니다.
Quiz 3: Beyond the node level
Question 1 [Fat tree topology]: 위의 DGX H100 다이어그램을 사용하여 노드 수준에서 전체 1024 GPU pod의 이등분 대역폭을 계산하세요. 각 링크의 대역폭이 전체 이등분 대역폭을 보장하도록 선택되었음을 보여주세요. 힌트: 링크 대역폭과 스위치 대역폭을 모두 계산해야 합니다.
답을 보려면 여기를 클릭하세요.
Answer: 구성 요소별로 해봅시다:
- 먼저 각 노드에는 leaf 스위치에 연결하는 8x400Gbps NDR IB 케이블이 있어 각 노드에 leaf까지
8 * 400 / 8 = 400 GB/s의 대역폭을 제공합니다. 3.2TB/s(64 400 GBps 링크)를 가진 8개의 leaf 스위치가 있지만, SU에서 수신(ingress)하기 위해 64개 포트 중 32개만 사용할 수 있으므로 32개 노드에 대해32 * 400 / 8 = 12.8TB/s, 다시 정확히 400GB/s입니다. - 그런 다음 spine 수준에서 각 SU를 spine에 연결하는
8 * 16 * 2400Gbps NDR IB 케이블이 있어 각 SU에 leaf까지8 * 16 * 2 * 400 / 8 = 12.8 TB/s의 대역폭을 제공합니다. 다시 말하지만, 이는 노드당 400GB/s입니다. 각각 3.2TB/s를 가진 16개의 spine 스위치가 있어16 * 3.2 = 51.2 TB/s를 제공하며, 128개 노드의 경우 다시 400GB/s입니다.
따라서 어떤 방식으로든 노드를 이등분하면 그들 사이에 GPU당 400GB/s가 있습니다. 모든 구성 요소는 fat tree를 보장하기 위해 정확히 필요한 대역폭을 가지고 있습니다.
Question 2 [Scaling to a larger DGX pod]: 1024개 대신 2048개 GPU에서 훈련하고 싶다고 가정해 봅시다. 이를 처리하기 위해 위의 DGX 토폴로지를 수정하는 가장 간단하고 좋은 방법은 무엇일까요? 4096개라면 어떨까요? 힌트: 정답은 없지만 비용을 낮추도록 노력하세요. 링크 용량을 염두에 두세요. 이 문서가 도움이 될 수 있습니다.
답을 보려면 여기를 클릭하세요.
Answer: 한 가지 옵션은 SU 구조(8개 스위치 아래 32개 노드)를 그대로 유지하고 더 많은 최상위 스위치와 함께 더 많이 추가하는 것입니다. 2배 더 많은 spine 스위치가 필요하므로 충분한 대역폭을 제공하는 32개의 spine 스위치가 있는 8개의 SU가 됩니다.
이것의 한 가지 문제는 leaf 스위치당 포트가 64개뿐이고 위 다이어그램에서 이미 모두 사용하고 있다는 것입니다. 그러나 대신 spine당 2x 대신 1x 400 Gbps NDR 케이블을 수행하는 것이 쉽고, 이는 동일한 총 대역폭을 제공하지만 일부 포트를 절약합니다.
4096 GPU의 경우 실제로 포트가 부족하므로 또 다른 간접 수준, 즉 계층 구조의 또 다른 수준을 추가해야 합니다. NVIDIA는 이를 “core switches”라고 부르며 128개의 spine 스위치와 64개의 core 스위치로 4096 GPU 클러스터를 구축합니다. 수학적으로 계산하여 이것이 충분한 대역폭을 제공함을 보여줄 수 있습니다.
How Do Collectives Work on GPUs?
GPU는 TPU와 동일한 모든 collectives를 수행할 수 있습니다: ReduceScatters, AllGathers, AllReduces, AllToAlls. TPU와 달리, 이것들이 작동하는 방식은 노드 수준(NVLink를 통해)에서 수행되는지 그 이상(InfiniBand를 통해)에서 수행되는지에 따라 변경됩니다. 이러한 collectives는 NVIDIA의 NVSHMEM 및 NCCL (“nickel”로 발음) 라이브러리에 의해 구현됩니다. NCCL은 여기에 오픈 소스로 공개되어 있습니다. NCCL은 지연 시간 요구 사항/토폴로지(세부 정보)에 따라 다양한 구현을 사용하지만, 여기부터는 스위치드 트리 패브릭(switched tree fabric)에 대한 이론적으로 최적의 모델에 대해 논의하겠습니다.
Intra-node collectives
AllGather or ReduceScatter: 노드 수준에서의 AllGather 또는 ReduceScatter의 경우 TPU처럼 링 주위로 수행할 수 있으며 각 홉에서 전체 GPU-to-GPU 대역폭을 사용합니다. GPU를 임의로 정렬하고 전체 GPU-to-GPU 대역폭을 사용하여 링 주위로 배열의 일부를 보냅니다.
이것이 TPU와 정확히 동일하다는 것을 알 수 있습니다. AllReduce의 경우 평소와 같이 RS + AG를 결합하여 두 배의 비용으로 수행할 수 있습니다.

지연 시간이 걱정된다면(예: 배열이 매우 작은 경우), 2개, 4개, 8개 쌍 내에서 AllReduce를 수행하여 $N - 1$ 대신 총 $\log(N)$ 홉으로 트리 축소를 수행할 수 있지만 총 비용은 여전히 동일합니다.
Takeaway: 단일 노드 내에서 B 바이트 배열을 AllGather하거나 ReduceScatter하는 비용은 약 $T_\text{comms} = B * (8 - 1) / (8 * W_\text{GPU egress}) \approxeq B / W_\text{GPU egress}$입니다. 이는 이론적으로 H100에서 $B / \text{450e9}$, B200에서 $B / \text{900e9}$ 정도입니다. AllReduce는 in-network reductions가 활성화되지 않는 한 비용이 2배입니다.
Pop Quiz 1 [AllGather time]: 450 GB/s 전이중 대역폭을 가진 8xH100 노드를 사용하여 AllGather(bf16[BX, F])는 얼마나 걸릴까요? $B=1024$, $F=16,384$라고 가정합니다.
답을 보려면 여기를 클릭하세요.
Answer: 총 $2 \cdot B \cdot F$ 바이트와 450e9 단방향 대역폭이 있습니다. 이것은 대략 $T_\text{comms} = (2 \cdot B \cdot F) / \text{450e9}$, 더 정확하게는 $(2 \cdot B \cdot F \cdot (8 - 1)) / (8 \cdot \text{450e9})$가 걸릴 것입니다. 제공된 값을 사용하면 대략 $(2 \cdot 1024 \cdot 16384) / \text{450e9} = \text{75us}$, 더 정확하게는 $\text{65us}$를 제공합니다.
AllToAlls: 노드 내의 GPU는 all-to-all 연결을 가지고 있어 AllToAll이 꽤 쉽습니다. 각 GPU는 대상 노드로 직접 보냅니다. 노드 내에서 B 바이트에 대해 각 GPU는 $B / N$ 바이트를 가지고 $(B / N^2)$ 바이트를 $N - 1$ 대상 노드로 보내 총
\[T_\text{AllToAll comms} = \frac{B \cdot (N - 1)}{W \cdot N^2} \approx \frac{B}{W \cdot N}\]비용은 $B / (4W)$인 TPU와 비교해 보세요. 따라서 단일 노드 내에서 이론적으로 런타임이 2배 빨라집니다($B / 4W$ 대 $B / 8W$).
Mixture of Expert (MoE) 모델의 경우, 출력 차원의 $N$개 샤드 중 최대 $k$개가 0이 아님을 보장하는 sparse or ragged AllToAll을 자주 원합니다. 즉, $T_\text{AllToAll} \rightarrow K[B, N]$ 여기서 각 축의 $N$개 항목 중 최대 $k$개가 0이 아닙니다. 이것의 비용은 $k/N$만큼 감소하여 총 약 $\min(k/N, 1) \cdot B / (W \cdot N)$이 됩니다. MoE의 경우 0이 아닌 값을 무작위로 독립적으로 선택하는 경우가 많으므로 $k$보다 적은 0이 아닐 확률이 있어 대략 $(N-1)/N \cdot \min(k/N, 1) \cdot B / (W \cdot N)$을 제공합니다.
Pop Quiz 2 [AllToAll time]: 450 GB/s 단방향 대역폭을 가진 8xH100 노드를 사용하여 AllToAllX->N(bf16[BX, N])은 얼마나 걸릴까요? 8개 항목 중 4개만 0이 아닐 것이라는 것을 알고 있다면 어떻게 될까요?
답을 보려면 여기를 클릭하세요.
Answer: 위에서, 밀집된 경우 비용은 $B \cdot (N-1) / (W \cdot N^2)$, 또는 $B / (W \cdot N)$이라는 것을 알고 있습니다. 항목의 $\frac{1}{2}$만 비-패딩이라는 것을 안다면 $B \cdot k/N / (W \cdot N) = B / (2 \cdot W \cdot N)$를 보낼 수 있으며, 대략 전체 비용의 절반입니다.
Takeaway: 단일 노드 내 GPU에서 $B$ 바이트 배열에 대한 AllToAll 비용은 약 $T_\text{comms} = (B \cdot (8 - 1)) / (8^2 \cdot W_\text{GPU egress}) \approx B / (8 \cdot W_\text{GPU egress})$입니다. ragged (top-$k$) AllToAll의 경우 $(B \cdot k) / (64 \cdot W_\text{GPU egress})$로 더욱 감소합니다.
Empirical measurements: 다음은 8xH100 노드에 대한 AllReduce 대역폭의 실증적 측정입니다. Algo BW는 측정된 대역폭(바이트 / 런타임)이고 Bus BW는 $2 \cdot W \cdot (8 - 1) / 8$로 계산되며 이론적으로 실제 링크 대역폭의 척도입니다. 450GB/s보다는 작지만 상당히 가까운 370GB/s에 도달하는 것을 볼 수 있지만, 디바이스당 약 10GB일 때만 그렇습니다. 이는 이러한 추정치가 이론적으로는 정확하지만 이를 실현하려면 큰 메시지가 필요함을 의미합니다.

이것은 실제 문제입니다. 예를 들어 LLaMA-3 70B의 MLP(bf16[8192, 28672] 크기, 또는 8방향 모델 샤딩의 경우 bf16[8192, 3584] = 58MB)와 같은 합리적인 크기의 배열에 대한 AllReduce조차도 피크 450GB/s에 비해 약 150GB/s만 달성할 수 있기 때문에 우리가 할 수 있는 이론적 주장을 의미 있게 복잡하게 만듭니다. 이에 비해 TPU는 훨씬 낮은 메시지 크기에서 피크 대역폭을 달성합니다(부록 B 참조).
Takeaway: NVIDIA는 H100 NVLink를 통해 약 450GB/s의 대역폭을 주장하지만 실제로는 370 GB/s를 초과하기 어려우므로 위의 추정치를 그에 따라 조정하세요.
In network reductions: Hopper 세대부터 NVIDIA 스위치는 “SHARP” (Scalable Hierarchical Aggregation and Reduction Protocol)를 지원하여 “in-network reductions”를 허용합니다. 이는 네트워크 스위치 자체가 축소 작업을 수행하고 결과를 여러 대상 GPU로 다중화하거나 “MultiCast”할 수 있음을 의미합니다:

이론적으로 이는 각 GPU가 데이터를 최상위 스위치로 보내고 스위치가 축소를 수행하고 각 GPU를 두 번 송신할 필요 없이 결과를 각 GPU로 브로드캐스트할 수 있음을 의미하므로 AllReduce 비용을 거의 절반으로 줄이며, 네트워크 지연 시간도 줄입니다.
\[T_\text{SHARP AR comms} = \frac{\text{bytes}}{\text{GPU egress bandwidth}}\]각 GPU가 먼저 $B \cdot (N - 1) / N$을 송신한 다음, 로컬 샤드의 부분적으로 축소된 버전을 수신(ingress of $B/N$)하고, 축소를 완료한 다음, $B/N$을 다시 송신하고, 완전히 축소된 결과를 수신(ingress of $B \cdot (N - 1) / N$)하여 정확히 $B$ 바이트를 수신하게 되므로 이것은 $1/N$의 계수만큼 차이가 나지 않고 정확합니다.
그러나 실제로는 SHARP가 활성화된 경우 예상되는 75%에 비해 약 30%의 대역폭 증가를 봅니다. 이것은 2배에 가깝지 않은 약 480GB/s 유효 collective 대역폭까지만 우리를 데려갑니다.

Takeaway: 이론적으로 NVIDIA SHARP(대부분의 NVIDIA 스위치에서 사용 가능)는 $B$ 바이트에 대한 AllReduce 비용을 약 $2 * B / W$에서 $B / W$로 줄여야 합니다. 그러나 실제로는 대역폭이 약 30% 향상되는 것을 봅니다. 순수 AllReduce는 LLM에서 매우 드물기 때문에 이것은 특별히 유용하지 않습니다.
Cross-node collectives
노드 수준을 넘어서면 비용이 조금 더 미묘해집니다. 트리 전체에서 축소를 수행할 때, 먼저 노드 내에서, 그 다음 leaf 수준에서, 그리고 spine 수준에서 각 수준의 일반 알고리즘을 사용하여 상향식으로 축소한다고 생각할 수 있습니다. 특히 AllReduce의 경우 노드 수준에서 AllReduce한 후 $B * N$ 대신 $B$ 바이트만 leaf로 송신하면 되기 때문에 전체적으로 더 적은 데이터를 통신할 수 있음을 알 수 있습니다.
얼마나 비쌀까요? 1차 근사로, 완전한 이등분 대역폭을 가지고 있기 때문에 AllGather 또는 ReduceScatter의 비용은 트리 축소의 세부 사항에 관계없이 대략 바이트 단위의 버퍼 크기를 노드 송신 대역폭(H100의 경우 400GB/s)으로 나눈 것입니다.
\[T_\text{AG or RS comms} = \frac{\text{bytes}}{W_\text{node egress}} \underset{H100}{=} \frac{\text{bytes}}{\text{400e9}}\]여기서 $W_\text{node}$ 송신은 일반적으로 위의 H100 네트워크(각 노드를 송신하는 8x400Gbps IB 링크)의 경우 400GB/s입니다. 이것을 가장 깔끔하게 상상하는 방법은 클러스터의 모든 노드에 대해 링 축소를 수행하는 것을 상상하는 것입니다. fat tree 토폴로지 덕분에 우리는 항상 임의의 두 노드 사이에 $W_\text{node}$ 송신으로 링을 구성하고 일반 축소를 수행할 수 있습니다. 노드 수준 축소는 더 높은 전체 대역폭과 더 나은 지연 시간을 가지므로 (거의) 병목 현상이 되지 않을 것입니다. 일반적으로 비용은 다음과 같습니다.
\[T_\text{total} = \max(T_\text{comms at node}, T_\text{comms in scale-out network}) = \max\left[\frac{\text{bytes}}{W_\text{GPU egress}}, \frac{\text{bytes}}{W_\text{node egress}}\right]\]여기에서 더 정확한 유도를 볼 수 있습니다.
우리는 사실상 네트워크의 각 계층에서 링 축소를 수행하고 있으며, 이를 대부분 중첩할 수 있으므로 다음과 같이 더 정확하게 말할 수 있습니다:
\[T_\text{AG or RS comms} = \text{bytes} \cdot max_\text{depth i}\left[\frac{D_i - 1}{D_i \cdot W_\text{link i}}\right]\]여기서 $D_i$는 깊이 $i$에서의 차수(깊이 $i$에서의 자식 수), $W_\text{link i}$는 각 자식을 노드 $i$에 연결하는 링크의 대역폭입니다.
이를 사용하여 주어진 토폴로지에 대해 이용 가능한 AllGather/AllReduce 대역폭을 $min_\text{depth i}(D_i * W_\text{link i} / (D_i - 1))$로 계산할 수 있습니다. 위의 경우:
- Node: $W_\text{link i}$ = 450GB/s인 8개의 GPU가 노드에 있으므로 $D_\text{node}$ = 8입니다. 따라서
450e9 * 8 / (8 - 1) = 514GB/s의 AG 대역폭을 가집니다. - Leaf: $W_\text{link i}$ = 400GB/s(8x400Gbps IB 링크)인 SU에 32개의 노드가 있으므로 $D_\text{leaf}$ = 32입니다. 따라서 대역폭은
400e9 * 32 / (32 - 1) = 413GB/s입니다. - Spine: $W_\text{link i}$ = 12.8TB/s(위의
8 * 16 * 2 * 400Gbps링크에서)인 4개의 SU가 있으므로 $D_\text{spine}$ = 4입니다. 대역폭은12.8e12 * 4 / (4 - 1) = 17.1TB/s입니다.
따라서 전반적인 AG 또는 RS 대역폭은 leaf 수준에서 min(514GB/s, 413GB/s, 17.1TB/s) = 413GB/s이므로 실제로는 $T_\text{AG or RS comms} = B / \text{413GB/s}$, 즉 최상위 수준에서도 약 413GB/s의 AllReduce 대역폭을 가집니다. SHARP를 사용한 AllReduce의 경우 $(N - 1) / N$ 요소가 없으므로 이보다 약간 낮을 것입니다(약 400GB/s). 그래도 450GB/s와 400GB/s는 근사치로 사용하기에 충분히 가깝습니다.
Other collectives: AllReduce는 SHARP가 활성화되지 않는 한 여전히 위 비용의 2배입니다. NVIDIA는 SHARP 지원 IB 스위치도 판매하지만 모든 공급자가 가지고 있는 것은 아닙니다. AllToAll은 AllReduce처럼 “계층적”이지 않기 때문에 노드 간 변경이 꽤 큽니다. 모든 GPU에서 다른 모든 GPU로 데이터를 보내고 싶다면 노드 수준에서 완전한 이등분 대역폭을 활용할 수 없습니다. 즉, $M = N / 8$ 노드에 걸친 N방향 AllToAll이 있는 경우 비용은
\[T_\text{AllToAll comms} = \frac{B \cdot (M - 1)}{M^2 \cdot W_\text{node egress}} \approxeq \frac{B}{M \cdot W_\text{node egress}}\]사실상 400GB/s가 아닌 50GB/s의 대역폭을 가집니다. 단일 H100 노드 내의 $B / (8 * \text{450e9})$에서 2개 노드에 걸칠 때 $B / (2 \cdot \text{400e9})$로 이동하여 4배 이상의 저하가 발생합니다.
다음은 1024-GPU DGX H100 SuperPod 아키텍처 요약입니다:
| Level | Number of GPUs | Degree (# Children) | Switch Bandwidth (full-duplex, TB/s) | Cable Bandwidth (full-duplex, TB/s) | Collective Bandwidth (GB/s) |
|---|---|---|---|---|---|
| Node | 8 | 8 | 6.4 | 3.6 | 450 |
| Leaf (SU) | 256 | 32 | 25.6 | 12.8 | 400 |
| Spine | 1024 | 4 | 51.2 | 51.2 | 400 |
우리는 GPU 또는 노드를 송신할 수 있는 유효 대역폭을 설명하기 위해 “Collective Bandwidth”라는 용어를 사용합니다. 또한 $\text{bisection bandwidth} * 2 / N$입니다.
Takeaway: 노드 수준을 넘어서면 B 바이트에 대한 AllGather 또는 ReduceScatter 비용은 대략 $B / W_\text{node egress}$이며, 이는 H100 DGX SuperPod에서 $B / \text{400e9}$이고, AllReduce는 SHARP가 활성화되지 않는 한 비용이 두 배입니다. 전체 토폴로지는 임의의 두 노드 쌍 사이에 일정한 대역폭을 제공하도록 설계된 fat tree입니다.
Reductions when array is sharded over a separate axis: 다음과 같은 축소를 고려해 봅시다.
\[\text{AllReduce}_X(A[I_Y, J]\ \{ U_X \})\]여기서 우리는 그 자체로 다른 축 $Y$를 따라 샤딩된 배열에 대해 AllReduce하고 있습니다. TPU에서 이 작업의 전체 비용은 샤딩되지 않은 버전에 비해 $1 / Y$배로 줄어듭니다. 축당 $1 / Y$만큼의 데이터를 보내기 때문입니다. GPU에서 비용은 어떤 축이 “내부” 축인지(노드 내 대 노드 간)와 각 샤드가 단일 노드 이상에 걸쳐 있는지 여부에 따라 다릅니다. $Y$가 내부 축이고 배열에 총 $\text{bytes}$ 바이트가 있다고 가정하면 전체 비용은 효과적으로 $Y$만큼 줄어들지만 $Y$가 여러 노드에 걸쳐 있는 경우에만 해당됩니다:
\[T_\text{comms at node} = \frac{\text{bytes}}{W_\text{GPU egress}} \cdot \frac{1}{\min(Y, D_\text{node})}\] \[T_\text{comms in scale-out network} = \frac{\text{bytes}}{W_\text{node egress}} \cdot \frac{D_\text{node}}{\max(D_\text{node}, Y)}\] \[T_\text{total} = \max(T_\text{comms at node}, T_\text{comms in scale-out network})\]여기서 N은 GPU 수이고 다시 $D_\text{node}$는 노드의 GPU 수(노드의 차수)입니다. 보시다시피 $Y < D_\text{node}$이면 노드 수준에서 이득을 얻지만 일반적으로 전체 런타임 감소를 보지 못하는 반면, $Y > D_\text{node}$이면 걸쳐 있는 노드 수에 비례하는 속도 향상을 얻습니다.
링 축소에 대해 정확하고 싶다면 트리 AllGatherX(AY { UX }) (Y가 내부 축이라고 가정)에 대한 일반적인 규칙은 다음과 같습니다.
\[T_\text{AR or RS comms} = \text{bytes} \cdot \max_{\text{depth } i}\left[\frac{D_i - 1}{D_i \cdot \max(Y, S_{i-1}) \cdot W_{\text{link } i}}\right]\]여기서 $S_i$는 M * N * …, 트리에서 레벨 i 아래 하위 노드의 크기입니다. 이것은 대략 우리가 걸쳐 있는 GPU 또는 노드가 많을수록 사용 가능한 대역폭이 커지지만 해당 노드 내에서만 그렇다는 것을 말해줍니다.
Pop Quiz 3 [Sharding along 2 axes]: $Y$가 단일 SU(256 칩)에 대한 내부 축인 $\text{AllGather}_X(\text{bf16}[D_X, F_Y])$를 수행하고 싶다고 가정해 봅시다. $D$, $F$, $Y$의 함수로서 이것은 얼마나 걸릴까요?
답을 보려면 여기를 클릭하세요.
Answer: Y <= 8일 때와 Y > 8일 때 두 가지 경우로 나눌 수 있습니다. $Y <= 8$일 때, 우리는 leaf 스위치에 의해 제한된 상태로 유지되므로 정답은 평소와 같이 $T_\text{comms} = 2 * D * F * (32 - 1) / (32 * 400e9)$입니다. Y > 8일 때, 우리는 위에서 대략 다음을 얻습니다.
\[T_\text{comms} = \frac{2 \cdot D \cdot F \cdot 256}{Y \cdot \text{12.8e12}} = \frac{2DF}{Y \cdot \text{50GB/s}}\]D = 8192, F = 32,768의 경우:

정확히 8방향 모델 병렬 처리를 수행하면 실제로 노드 수준 축소 비용을 8만큼 줄이지만 전체 비용은 동일하게 유지하므로 무료지만 전체 대역폭을 개선하는 데는 도움이 되지 않는다는 점에 유의하세요.
Takeaway: 여러 샤딩 축이 있는 경우 외부 축소 비용은 내부 축이 걸쳐 있는 노드 수만큼 감소합니다.
Quiz 4: Collectives
Question 1 [SU AllGather]: M개 노드와 노드당 N개 GPU가 있는 단일 SU만 고려해 봅시다. AllGather 중에 노드 수준 스위치에 의해 정확히 몇 바이트가 수신(ingress)되고 송신(egress)되나요? 최상위 스위치는 어떤가요?
답을 보려면 여기를 클릭하세요.
Answer: 축소의 구성 요소를 통해 단계별로 해봅시다:
- 각 GPU는 스위치로 $B / MN$ 바이트를 보내 총 수신은 $NB / MN = B / M$ 바이트입니다.
- 전체 $B / M$ 바이트를 spine 스위치로 송신합니다.
- spine 스위치로부터 $B * (M - 1) / M$ 바이트를 수신합니다.
- $B - B / MN$ 바이트를 $N$회 송신하여 총 $N * (B - B / MN) = NB - B / M$입니다.
총합은 $B$ 수신 및 $BN$ 송신이므로 송신에 의해 병목이 발생해야 하며 총 시간은 $T_\text{AllGather} = BN / W_\text{node} = B / \text{450e9}$가 될 것입니다.
spine 스위치의 경우 수학은 실제로 더 간단합니다. $B / M$ 바이트가 M번 수신되어야 하며(총 $B$ 바이트), 그런 다음 $B (M - 1) / M$이 $M$번 송신되어 총 $B * (M - 1)$이 나갑니다. 이것이 훨씬 크기 때문에 비용은 $T_\text{AllGather} = B \cdot (M - 1) / (M \cdot W_\text{node}) = B \cdot (M - 1) / (M \cdot \text{400e9})$입니다.
Question 2 [Single-node SHARP AR]: 노드당 N개 GPU가 있는 단일 노드를 고려해 봅시다. SHARP(in-network reductions)를 사용하는 AllReduce 중에 스위치에 의해 정확히 몇 바이트가 수신되고 송신되나요?
답을 보려면 여기를 클릭하세요.
Answer: 이전과 마찬가지로 단계별로 해봅시다.
- 각 GPU는 $B * (N - 1) / N$ 바이트를 보내므로 $N * B * (N - 1) / N = B * (N - 1)$이 수신됩니다.
- 부분 합을 누적하고 각 GPU에 $B / N$ 바이트를 다시 보내므로 $N * B / N = B$ 바이트가 송신됩니다.
- 잔차에 대해 로컬에서 부분 합을 수행한 다음 이를 다시 스위치로 보냅니다. 이것은 총 $N * B / N = B$ 바이트 수신입니다.
- 모든 샤드를 캡처하고 멀티캐스트하여 $B * (N - 1) / N$을 $N$개 대상으로 보내 총 $B * (N - 1) / N * N = B * (N - 1)$이 송신됩니다.
따라서 총합은 $B * (N - 1) + B = BN$ 바이트 수신 및 송신입니다. 이는 전체 처리량이 정확히 $B / W_\text{egress}$임을 뒷받침합니다.
Question 3 [Cross-node SHARP AR]: N개 GPU의 단일 노드에 걸쳐 샤딩된 bf16[DX, FY] 배열을 고려해 봅시다. AllReduce(bf16[D, FY] { UX })는 얼마나 걸릴까요? in-network reductions를 수행한다고 가정할 수 있습니다. 단일 노드 이상인 경우 이것이 어떻게 다른지 설명하세요.
답을 보려면 여기를 클릭하세요.
Answer: 위 질문에 대한 답을 수정해 볼 수 있습니다. 기본적으로 각 GPU에서 $B * (X - 1) / XY$ 바이트를 먼저 송신한 다음 각 GPU에 $B / XY$를 다시 보내고, 그 양만큼 다시 스위치로 보낸 다음 각 GPU에 $B * (X - 1) / XY$를 다시 보냅니다. 총합은 $NB / Y$ 수신 및 송신이므로 총 시간은 $T_\text{comms} = NB / (Y * N * W_\text{link}) = N * 2DF / (Y * N * W_\text{link}) = 2 * D * F / (Y * W_\text{link})$이므로 총 시간은 실제로 $Y$에 따라 감소합니다.
단일 노드를 넘어서면 위와 거의 같은 축소를 수행할 수 있지만 노드 수준 스위치를 송신할 때 $B / Y$가 아닌 모든 B 바이트를 보내야 합니다. 각 샤드를 별도로 유지해야 하기 때문입니다.
Question 4 [Spine level AR cost]: 위와 동일한 설정이지만 $Y = 256$인 경우를 고려해 봅시다 (따라서 AR은 spine 수준에서 발생). AllReduce는 얼마나 걸릴까요? 다시 in-network reductions를 가정해도 좋습니다.
답을 보려면 여기를 클릭하세요.
Answer: 이것은 spine 수준에서 다소 우스꽝스러운 양의 대역폭을 활용할 수 있게 해줍니다. 4개 노드에 걸쳐 25.6TB/s의 대역폭이 있으므로 6.4TB/s의 AllReduce 대역폭이 있습니다. SHARP를 사용하면 2 * D * F / 6.4e12초만큼 적게 걸릴 수 있습니다.
Question 5 [2-way AllGather cost]: 정확히 2개 노드에 걸친 $B$ 바이트의 AllGather의 정확한 비용을 계산하세요. 근사치가 아닌 정확한 비용을 계산하고 노드 내 비용과 노드 간 비용을 모두 고려하세요.
답을 보려면 여기를 클릭하세요.
Answer: 노드 수준에서는 $T_\text{comms} = B * 7 / (8 * \text{450e9}) = B / \text{514e9}$인 반면 그 너머에서는 실제로 $T_\text{comms} = B * (2 - 1) / (2 * \text{400e9}) = B / \text{800e9}$입니다. 따라서 우리는 leaf 수준이 아니라 노드 수준 축소에 의해 제한됩니다! 이것은 예를 들어 2방향 데이터 병렬 처리를 수행하는 DeepSeek v3에 동기를 부여합니다.
Rooflines for LLM Scaling on GPUs
이제 이 모든 것이 무엇을 향해 구축되었는지 살펴봅시다: GPU에서의 LLM 확장에 대한 루프라인 이해하기. 이것은 여기의 TPU 훈련 챕터를 보완하기 위함입니다. 거기서 했듯이, 여기서의 목표는 다양한 병렬 처리 전략에 대한 총 $T_\text{math}$ 및 $T_\text{comms}$를 살펴보고 $T_\text{comms} > T_\text{math}$가 되는 지점을 이해하는 것입니다. 이전과 마찬가지로 다음 연산을 가진 MLP 블록만 고려합니다.
\[\text{MLP}(x) \equiv x[B, D] *_D W_\text{in}[D, F] \cdot_F W_\text{out}[F, D]\]여기서 $B$는 토큰 단위의 글로벌 배치 크기입니다(즉 $B = \text{batch size} \cdot \text{sequence length}$).
여기에 GPU 및 노드 수준 모두에서 유효 대역폭을 보여주는 위 표를 재현합니다:
| Node Type | GPUs per node | GPU egress bandwidth | Node egress bandwidth |
|---|---|---|---|
| H100 | 8 | 450e9 | 400e9 |
| B200 | 8 | 900e9 | 400e9 |
| GB200 NVL72 | 72 | 900e9 | 3600e9 |
Note: GPU와 노드 송신 대역폭 모두 LLM에 대한 루프라인을 결정합니다. 우리는 노드 수준 내에서 또는 그 이상에서 작동하는지에 따라 GPU 또는 노드 대역폭을 설명하기 위해 $W_\text{collective}$라는 용어를 사용할 것입니다.
TPU에 대해 했던 것처럼 데이터 병렬 처리, 텐서 병렬 처리, 파이프라인 병렬 처리, 전문가 병렬 처리 및 그 조합에 대한 컴퓨팅 통신 루프라인을 살펴봅시다. 이 섹션의 나머지 부분에서는 특정 계산을 위해 H100 루프라인에 초점을 맞출 것입니다. GB200-NVL72는 동일한 일반 루프라인을 갖지만 더 큰 노드 송신 대역폭을 가지고 있기 때문에 때때로 노드 수준에서 병목 현상이 발생할 수 있습니다.
Data Parallelism
앞서 언급했듯이 DP 및 ZeRO 샤딩은 역방향 패스에서 가중치 AllReduce 또는 ReduceScatter + AllGather를 포함합니다. 이 둘은 비용이 동일하므로, in-network reductions 없이 순수 데이터 병렬 처리 또는 FSDP에 대해 compute-bound가 되려면 역방향 패스에서 크기 X의 축으로 레이어당 다음을 갖습니다:
\[T_\text{math} = \frac{2 \cdot 2 \cdot 2 \cdot BDF}{X \cdot C}\] \[T_\text{comms} = \frac{2 \cdot 2 \cdot 2 \cdot DF}{W_\text{collective}}\]따라서 $T_\text{math} > T_\text{comms}$를 위해 $B / (XC) > 1 / W_\text{collective}$ 또는
\[\frac{B}{X} > \frac{C}{W_\text{collective}}\]여기서 $W_\text{collective}$는 노드 내에서 샤딩하는지 또는 노드 간에 샤딩하는지에 따라 GPU 또는 노드 수준 송신 대역폭입니다. 따라서:
- Within a node, GPU당 토큰 배치 크기 > $\text{990e12} / \text{450e9} = 2200$만 필요합니다.
- Within an SU or at the spine level, BS > $\text{990e12} / \text{400e9} = 2475$.
이것은 TPU보다 꽤 높은데, TPU에서는 세 축 모두에서 850입니다. 예를 들어, 16000개의 H100에서 훈련된 LLaMA-3는 최소 40M 토큰의 배치 크기가 필요합니다(참고로 그들은 16M을 사용했습니다). 450GB/s의 H100 대신 더 낮은 300GB/s 대역폭의 2048개 H800 GPU에서 훈련된 DeepSeek v3는 GPU당 $\text{990e12} / \text{300e9} = 3300$ 토큰, 또는 약 6.7M이 필요합니다(실제로는 4M을 사용했습니다).
In-network reductions가 활성화되고 순수 데이터 병렬 처리를 사용하면 이론적으로 2배의 AllReduce 대역폭을 갖게 되어 이 두 숫자를 모두 절반으로 줄일 수 있습니다. 그러나 실제로는 이점이 30%에 가깝고, 이는 우리가 일반적으로 보고된 숫자에 도달하기 위해 고군분투한다는 사실을 만회하는 정도에 불과합니다. 또한 순수 데이터 병렬 처리는 거의 유용하지 않기 때문에 실제로는 기본적으로 중요하지 않습니다.
MoE models: E개의 전문가와 토큰당 k개의 전문가가 있는 Mixture of Experts (MoE) 모델의 경우 이는 다음과 같이 증가합니다.
\[T_\text{math} = \frac{2 \cdot 2 \cdot 2 \cdot k \cdot BDF}{X \cdot C}\] \[T_\text{comms} = \frac{2 \cdot 2 \cdot 2 \cdot EDF}{W_\text{collective}}\]이는 GPU당 토큰 배치 크기를 $E/k$배만큼 부풀립니다. 즉,
\[\frac{B}{X} > \frac{E}{k} \frac{C}{W_\text{collective}}\]예를 들어, $k=4$이고 $E=128$인 새로운 OpenAI OSS 모델의 경우, 이는 노드 전체에서 32 * 2475 = 79,200으로 증가하여 터무니없이 높은 숫자가 됩니다.
X가 작을 때는 어떻게 되나요? 예: 2노드 데이터 병렬 처리만 수행하는 경우 $(X - 1) / X$ 스케일링의 이점을 얻습니다.
\[T_\text{math} = \frac{2 \cdot 2 \cdot 2 \cdot BDF}{N * C}\] \[T_\text{comms} = \frac{2 \cdot 2 \cdot 2 \cdot DF \cdot (X-1)}{X \cdot W_\text{collective}}\]여기서 X는 노드 수이고 $N = 8 \cdot X$입니다. 그러면 밀집 모델의 경우 $B / N > \alpha \cdot (X - 1) / X$, 또는 예: $B / N > \text{1237}$로 위 값의 절반입니다. 이러한 이유로 2방향 데이터 병렬 처리를 꽤 자주 볼 수 있습니다.
Takeaway: 데이터 병렬 처리 및 ZeRO 샤딩은 완벽한 중첩 및 FLOPs 활용을 가정할 때 H100 또는 B200에서 compute-bound가 되기 위해 약 2500 토큰의 GPU당 배치 크기가 필요합니다. MoE 모델의 경우 이는 $E / k$(총 파라미터 대 활성화된 파라미터의 비율)만큼 증가합니다. 소량의 데이터 병렬 처리를 수행할 때 임계 배치 크기가 감소합니다.
Tensor Parallelism
Tensor parallelism은 활성화에 대한 AllGather 및 ReduceScatter를 필요로 하며, 이를 MLP FLOPs와 중첩시켜야 합니다. 즉, 순방향 패스에서 다음을 갖습니다.
\[T_\text{math} = \frac{2\cdot 2 \cdot BDF}{Y \cdot C}\] \[T_\text{comms} = \frac{2\cdot 2 \cdot BD}{W_\text{collective}}\]compute-bound가 되기 위한 규칙은 다음과 같습니다.
\[Y < \frac{F \cdot W_\text{collective}}{C}\]노드 내에서는 약 $F / 2200$ 또는 노드 밖에서는 $F / 2475$를 제공합니다. LLaMA-3와 같이 $F=\text{28000}$인 경우 약 11방향 TP(또는 내림하여 약 8방향, 이것이 노드 크기임)입니다. 위에서와 같이 정확히 2개 노드에 걸칠 때 추가 2배 대역폭을 얻으므로 일반적으로 16방향 데이터 병렬 처리($F > 2475 \cdot (Y - 8)$)를 수행할 수 있으며, 이는 이론적으로 최대 19방향 모델 병렬 처리를 제공합니다.
Takeaway: 피드포워드 차원 F를 가진 크기 Y 축에 대한 Tensor parallelism은 $Y > F / 2475$일 때 통신 병목이 발생하며, 이는 일반적으로 노드 내 TP 또는 최대 2노드 TP로 제한합니다.
Expert Parallelism
위에서 이미 언급했듯이 Mixture of Expert (MoE) 모델은 k배 더 많은 FLOPs만으로 E배 더 많은 모델 가중치를 가지므로 데이터 병렬 처리가 훨씬 어렵습니다. 가중치를 전문가 차원에 따라 샤딩하여 이를 어느 정도 완화할 수 있습니다. 즉, Win[EZ, D, F]. MLP 블록을 수행하려면 활성화를 해당 전문가에게 보내기 위해 2x AllToAll을 도입해야 합니다.
위에서 언급했듯이, 여러 노드에 걸쳐 있는 경우 이 AllToAllZ->k([B, D, k])의 비용은 대략 $T_\text{AllToAll} = 2 \cdot B \cdot D \cdot (Z-8)/Z \min(8 * k / Z, 1)$이므로 순수 전문가 병렬 처리를 위해서는 다음이 필요합니다.
\[T_\text{math} = \frac{4 \cdot B \cdot k \cdot D \cdot F}{Z \cdot C}\] \[T_\text{comms} = \frac{4 \cdot B \cdot D \cdot (Z-8)}{W \cdot Z} \cdot \min\left(\frac{8 \cdot k}{Z}, 1\right)\]$K > Z/8$이고 $F > \alpha \cdot (Z - 8)/k$이거나 $Z \gg K$이고 $F > 8 \cdot \alpha$가 필요합니다. 여기서 $\alpha = C/W$입니다. 이는 전문가 병렬 처리가 가능한 두 가지 도메인을 제공합니다. 하나는 소량의 전문가 병렬 처리(대략 2노드)와 작은 $F$를 가진 경우이고, 다른 하나는 큰 $F$와 임의로 큰 $Z$(최대 E방향 전문가 병렬 처리)를 가진 경우입니다.
실제로 두 가지 경우를 모두 볼 수 있습니다. 작은 양의 전문가 병렬 처리(매우 작은 F와 비교적 작고 제한된 노드 간 전문가 병렬 처리를 가진 DeepSeek v3와 같은) 또는 큰 F를 가진 모델의 경우 TP와 함께 상당한 노드 간 EP를 수행할 수 있습니다.
Takeaway: $F < 8 * C / W_\text{node}$이면 전문가 병렬 처리는 TP와 유사한(약간 낮은) 비용으로 1-2개 노드에 걸칠 수 있으며, $F > 8 * C / W_\text{node}$이면 비교적 저렴한 비용으로 상당한 양의 전문가 병렬 처리(최대 $E$ 노드)를 수행할 수 있습니다.
Pipeline Parallelism
Pipeline parallelism은 레이어를 노드에 분할하며, 몇 개의 레이어마다 활성화의 작은 마이크로배치만 보내기 때문에 통신 비용이 매우 낮습니다. 역사적으로 파이프라이닝은 “pipeline bubbles”로 어려움을 겪었지만, 새로운 제로 버블 파이프라이닝 접근 방식을 사용하면 일반적으로 없이 수행할 수 있습니다.
파이프라이닝의 전체 통신 비용은 아주 작습니다: $N_\text{MB}$ 마이크로배치와 $N_\text{stages}$가 있으면 $T_\text{comms per hop} = 2 \cdot B \cdot D / (W \cdot N_\text{MB})$이고 $N_\text{MB} + N_\text{stages} - 2$ 홉이므로 대략
\[T_\text{total PP comms} = \frac{2BD}{W \cdot N_\text{MB}} \cdot (N_\text{MB} + N_\text{stages} - 2)\] \[T_\text{per-layer comms} \approx 1.5 \cdot \frac{2BD}{W \cdot N_\text{layers}}\]$N_\text{layers}$로 나누기 때문에 이는 다른 어떤 비용보다 훨씬 작습니다. 즉, 통신 관점에서 파이프라이닝은 기본적으로 무료입니다. 그렇다면 왜 그냥 파이프라이닝을 하지 않을까요? 몇 가지 이유가 있습니다:
(1) Code complexity: 파이프라이닝은 다른 접근 방식만큼 자동 병렬화 프레임워크(XLA의 GSPMD와 같은)에 잘 맞지 않습니다. 파이프라인 버블을 숨기기 위해 마이크로배칭을 도입하기 때문에 프로그램 구조가 변경되며, 사용자 정의 제로 버블 파이프라인 일정은 순방향 및 역방향 패스의 복잡한 인터리빙을 요구하여 이 문제를 악화시킵니다.
(2) Pipelining makes data parallelism and FSDP hard: 아마도 파이프라이닝을 하지 않는 가장 큰 이유는 FSDP 및 데이터 병렬 처리와 잘 맞지 않기 때문일 것입니다. 특히 ZeRO-3 샤딩은 모든 마이크로배치에서 가중치를 AllGather해야 하는데, AllGather 비용을 상각할 토큰이 $B / N_\text{microbatches}$개밖에 없을 때는 제대로 작동하지 않습니다. 게다가 역방향 패스 중에 마지막 마이크로배치가 주어진 단계를 통과할 때까지 그라디언트를 AllReduce하거나 ReduceScatter할 수 없으므로, 중첩되지 않은 통신 시간이 상당히 발생합니다.

(3) Pipeline bubbles and step imbalance: 위 (나쁜) 파이프라인 일정에서 볼 수 있듯이 순진한 파이프라인 일정 중에는 상당한 버블(낭비되는 컴퓨팅을 의미)이 발생하기 쉽습니다. 위에서 두 번째 단계는 0단계에서 유휴 상태이고, 첫 번째 단계는 2단계에서 3단계까지 유휴 상태이며, 두 번째 단계는 마지막 단계에서 다시 유휴 상태입니다. 신중한 스케줄링으로 이를 어느 정도 피할 수 있지만 여전히 버블이 발생하는 경우가 많습니다. 또한 critical path에서 활성화를 한 단계에서 다음 단계로 전달해야 하므로 오버헤드가 추가될 수 있습니다:
이러한 각 문제에 대한 해결 방법이 있지만 구현하기 복잡하고 유지 관리하기 어렵지만, 파이프라이닝은 다른 방법에 비해 통신 비용이 낮은 기술로 남아 있습니다.
Caveat about latency: 앞서 언급했듯이 GPU는 꽤 큰 메시지로도 전체 AllReduce 대역폭을 달성하기 위해 고군분투합니다. 즉, 이론적으로 예를 들어 여러 노드에 걸쳐 전문가 병렬 AllToAll을 확장할 수 있더라도 전체 대역폭의 50%도 달성하기 어려울 수 있습니다. 이는 지연 시간 오버헤드를 최소화하기 위해 TP 또는 EP를 더 적은 수의 노드 내에 유지하려고 노력한다는 것을 의미합니다.
Examples
What does DeepSeek do? 참고로 DeepSeek V3는 2048개의 H800 GPU로 다음과 같이 훈련됩니다:
- 8개 노드에 걸친 64방향 Expert Parallelism (EP)
- 16방향 Pipeline Parallelism (PP)
- 2방향 ZeRO-1 Data Parallelism (DP)
그들은 4096 * 15360 = 62,914,560 토큰, 또는 GPU당 30k 토큰의 정상 상태 배치 크기를 가졌습니다. 이것이 이미 꽤 크다는 것을 알 수 있지만, 모델도 매우 희소하므로(k=8, E=256) 꽤 큰 배치 크기가 필요합니다. 64방향 EP와 16방향 PP를 사용하면 총 1024방향 모델 병렬 처리가 되며, 이는 AllReduce가 spine 수준에서 수행됨을 의미합니다. 2방향일 뿐이므로 실제로는 $2 / (2 - 1) = 2$배 더 많은 대역폭을 얻게 됩니다. 이는 또한 최종 파이프라인 단계와 겹치는 최종 데이터 병렬 AllReduce 비용을 줄이는 데 도움이 됩니다.
What does LLaMA-3 do? LLaMA-3는 16k GPU에서 16M 토큰의 BS로 훈련하며, 이는 GPU당 약 1k 토큰입니다. 그들은 다음을 수행합니다:
- 노드 내 8방향 Tensor Parallelism (TP)
- 16방향 Pipeline Parallelism (PP)
- 128방향 ZeRO-1 Data Parallelism
이것은 또한 밀집 모델이므로 일반적으로 이러한 것들은 꽤 사소합니다. 16방향 PP는 데이터 병렬 AllReduce 비용을 16배 줄여주며, 이는 임계 배치 크기를 줄이는 데 도움이 됩니다.
TLDR of LLM Scaling on GPUs
한 걸음 물러나 지금까지 배운 내용을 전반적으로 요약해 봅시다:
- Data parallelism 또는 FSDP (ZeRO-1/3)는 GPU당 약 2500 토큰의 로컬 배치 크기가 필요합니다. 이론적으로 in-network reductions + 순수 DP는 이를 다소 줄일 수 있습니다.
- Tensor parallelism은 약 8방향까지 compute-bound입니다. 그러나 comms-bound가 되기 전에 이 이상으로 확장할 대역폭이 부족합니다. 이는 주로 단일 NVLink 도메인(즉, 단일 노드 또는 최대 72개 GPU의 GB200NVL72 사용 필요)으로 제한됩니다.
- 여러 노드에 걸친 모든 형태의 모델 병렬 처리는 FSDP 비용을 더욱 줄일 수 있습니다. 따라서 우리는 종종 PP + EP + TP를 혼합하여 많은 노드를 교차하고 FSDP 비용을 줄이고 싶어합니다.
- Pipeline parallelism은 제로 버블 파이프라이닝의 코드 복잡성을 처리하고 데이터 병렬 병목 현상을 피하기 위해 배치 크기를 상당히 크게 유지할 수 있다면 잘 작동합니다. 파이프라이닝은 일반적으로 ZeRO-3를 불가능하게 만들지만(각 파이프라인 단계에서 AllGather해야 하므로), 대신 ZeRO-1을 수행할 수 있습니다.
높은 수준에서, 이것은 GPU에서 대규모 모델을 샤딩하기 위한 레시피를 제공합니다:
- 비교적 작은 밀집 모델의 경우, 배치 크기가 있다면 공격적인 FSDP가 훌륭하게 작동하며, 필요한 경우 약간의 파이프라이닝이나 텐서 병렬 처리를 사용할 수 있습니다.
- 더 큰 밀집 모델의 경우, 1-2 노드 TP + 다중 노드 PP + 순수 DP의 조합이 잘 작동합니다.
- MoE의 경우 위의 규칙이 적용되지만 TP보다 일반적으로 선호하는 전문가 병렬 처리도 수행할 수 있습니다. $F > 8 * C / W_\text{node}$인 경우 수많은 다중 노드 전문가 병렬 처리를 수행할 수 있지만, 그렇지 않으면 대략 2노드 EP로 제한됩니다.
Quiz 5: LLM rooflines
Question 1 [B200 rooflines]: B200 DGX SuperPod (GB200 NVL72 아님)는 노드 내 대역폭이 2배(900GB/s 송신)이지만 스케일 아웃 네트워크 대역폭은 동일(400GB/s)합니다 (출처). 총 FLOPs는 위에 보고되어 있습니다. 이것이 모델 및 데이터 병렬 루프라인을 어떻게 변경하나요?
답을 보려면 여기를 클릭하세요.
Answer: bfloat16의 FLOPs/s가 990에서 2250 TFLOPs로 2.25배 증가합니다. 2배의 대역폭으로 노드 내에서 루프라인은 거의 동일하게 유지됩니다. 예를 들어 TP의 경우 임계 intensity가 2250e12 / 900e9 = 2500으로 올라가므로 $Y < F / 2500$ 제한을 가지며, 이는 약간 더 높을 뿐입니다(노드 크기가 증가하지 않는 한 도움이 되지 않음).
그러나 노드를 넘어서면 추가 대역폭이 부족하여 compute-bound가 되기가 더 어렵습니다! 예를 들어 데이터 병렬 처리의 경우 GPU가 동일한 대역폭으로 훨씬 더 많은 FLOPs를 수행할 수 있기 때문에 임계 배치 크기가 2250e12 / 400e9 = 5625로 증가합니다.
72 GPU 노드가 있는 GB200 SuperPods는 더 많은 송신 대역폭을 추가하여 이를 변경합니다 (출처).
Question 2 [How to shard LLaMA-3 70B]: LLaMA-3 70B를 Adam과 fp32 옵티마이저 상태로 bfloat16에서 훈련한다고 가정해 봅시다.
- 최소한 가중치와 옵티마이저를 저장하기 위해 몇 개의 H100이 필요할까요?
- 15T 토큰에 대해 4096 H100 GPU에서 훈련하고 싶다고 가정해 봅시다. 45% MFU(Model FLOPs Utilization)를 달성했다고 합시다. 훈련하는 데 얼마나 걸릴까요?
- LLaMA-3 70B는
F = 28,672이고 약 4M 토큰의 배치 크기로 훈련되었습니다. comms-bound가 되지 않고 수행할 수 있는 최대 모델 병렬 처리는 얼마인가요? 이것과 순수 DP를 사용하여 4k 칩에서 compute-bound를 유지하면서 LLaMA-3를 훈련할 수 있을까요? ZeRO-3는 어떤가요? 8방향 파이프라이닝은 어떤가요? 참고: 통신 비용과 GPU 메모리 사용량을 모두 고려하세요.
답을 보려면 여기를 클릭하세요.
- 가중치에 2바이트, 옵티마이저 상태에 8바이트가 필요하므로 최소 700GB입니다. 80GB DRAM을 사용하면 최소 9개의 GPU, 또는 (반올림하여) 최소 2개의 8xH100 노드가 필요합니다. 훈련하는 데 영원히 걸리고 그라디언트 체크포인트를 보유하지 못하겠지만 하한선입니다.
- 이를 위해서는 총
6 * 70e9 * 15e12 = 6.3e24 bf16 FLOPs가 필요합니다. 각 GPU는990e12FLOPs를 수행할 수 있으므로 45% MFU에서 1.8e18 FLOPs/s를 수행할 수 있습니다. 따라서 전체 작업은 3.5e6 초, 즉 40일이 걸립니다. - 노드 내에서 450GB/s의 대역폭이 있으므로 한계는 대략
F / 1995 = 28672 / 1995 = 14.372입니다. 이는 2개 노드에 걸치지 않으므로 현실적으로 최대 8방향 모델 병렬 처리까지 갈 수 있습니다.- 이를 위해서는 512방향 DP를 수행해야 합니다. 먼저 메모리가 충분한지 확인해야 합니다. 모델이 8방향으로만 샤딩되므로
700GB / 8 = 87.5GB / GPU가 되는데, 이는 맞지 않으므로 안 됩니다! - ZeRO-3 및 8방향 TP를 사용하면 512방향 ZeRO-3를 수행하게 됩니다. 모든 것을 공격적으로 샤딩하고 있으므로 메모리 문제는 없습니다. GPU당 배치 크기는
4e6 / 4096 = 976이 됩니다. 이것은 꽤 낮으며 순수 DP 한계보다 낮습니다. 가중치를 이동해야 하므로 이 한계의 두 배입니다. 따라서 안 됩니다. - 8방향 파이프라이닝을 사용하면 각 모델 병렬 샤드가 이제 8개 노드에 걸쳐 있습니다. 보시다시피 이것은 leaf 수준 AllGather 비용을 8만큼 줄이므로 전체 AllReduce/AllGather 대역폭이 400GB/s에서
8 * 400GB/s = 3200GB/s로 이동합니다. 루프라인은990e12 / 3200e9 = 309이므로 우리는 괜찮을 것입니다! 파이프라이닝을 효율적으로 구현하기만 하면 됩니다.
- 이를 위해서는 512방향 DP를 수행해야 합니다. 먼저 메모리가 충분한지 확인해야 합니다. 모델이 8방향으로만 샤딩되므로
Question 3 [Megatron-LM hyperparams]: 높은 MFU 수치를 강조하는 Megatron-LM 리포지토리의 이 그림을 고려해 보세요.

시퀀스 길이는 모든 곳에서 4096입니다. 16B, 70B, 314B 모델의 경우 GPU당 토큰 배치 크기는 얼마인가요? 데이터 병렬 처리가 가장 바깥쪽 축이고 bfloat16 축소를 가정할 때, 이들 각각이 이론적으로 compute-bound인지 communication-bound인지, 그리고 더 최적의 구성이 있는지 결정하세요.
답을 보려면 여기를 클릭하세요.
Answer: GPU당 배치 크기부터 시작해 봅시다.
- 16B:
192 * 4096 / 192 = 4096tokens per GPU - 70B:
384 * 4096 / 768 = 2048tokens per GPU - 314B:
1536 * 4096 / 3072 = 2048tokens per GPU
즉, 첫 번째를 제외하고 이들은 모두 배치당 약 2k 토큰을 맴돌며, 이는 특히 우리가 FSDP에 대해 계산한 임계값 주위입니다. spine 수준 축소를 기반으로 해당 경계를 2,472 토큰 / GPU로 계산했으며, 이는 여기서 대략적으로 작용할 것입니다. 그러나 70B와 314B 모두 각각 16방향 및 64방향 모델(PP + TP) 샤딩을 가지고 있으므로 spine 수준에서 2배 및 8배 더 나은 처리량을 얻습니다. 즉, 각각 약 1k 및 300 tokens / step에서 compute-bound여야 합니다.
Acknowledgements and Further Reading
이 챕터는 다음을 포함한 많은 지식이 풍부한 GPU 전문가들의 도움에 크게 의존했습니다:
- GPU 커널 프로그래밍의 현실을 설명하는 데 도움을 준 Adam Paszke.
- GPU 네트워킹 작동 방식을 처음 설명해 준 Swapnil Patil.
- GPU의 경험적 현실이 주장된 사양과 다른 경우가 많다는 점을 지적한 Stas Bekman.
- 하드웨어 수준에서 GPU와 TPU가 어떻게 비교되는지 명확히 하는 데 도움을 준 Reiner Pope.
- 칩 수준 이야기에 대한 상세한 피드백을 제공한 Frédéric Bastien.
- GPU에서의 LLM 훈련 경험으로 루프라인 섹션을 개선하는 데 도움을 준 Nouamane Tazi.
- GPU가 네트워킹되는 방식과 NVIDIA의 사양이 현장에 배포되는 것과 어떻게 비교되는지 이해하는 데 도움을 준 Sanford Miller.
GPU에 대한 훌륭한 글이 많이 있지만 제가 가장 좋아하는 몇 가지는 다음과 같습니다:
- SemiAnalysis’ History of the NVIDIA Tensor Core: GPU가 비디오 게임 엔진에서 ML 가속기로 어떻게 변모했는지 설명하는 환상적인 기사입니다.
- SemiAnalysis’ Analysis of Blackwell Performance: 차세대 NVIDIA GPU를 이해하기 위해 읽을 가치가 있습니다.
- H100 DGX SuperPod Reference: 더 큰 GPU 클러스터가 네트워킹되는 방식에 대한 건조하지만 유용한 읽을거리입니다. 여기는 GB200 시스템에 대한 유사한 문서입니다.
- Hot Chips Talk about the NVLink Switch: NVLink 및 NCCL collectives, 특히 in-network reductions를 포함한 재미있는 읽을거리입니다.
- DeepSeek-V3 Technical Report: 그들이 샤딩 설정을 어떻게 선택했는지 설명하는 대규모 준공개 LLM 훈련 보고서의 좋은 예입니다.
- How to Optimize a CUDA Matmul: GPU에서의 캐시 일관성을 고려하여 CUDA Cores를 사용하여 효율적인 matmul을 구현하는 방법을 설명하는 훌륭한 블로그입니다.
- HuggingFace Ultra-Scale Playbook: 이 챕터에 부분적으로 영감을 준 GPU에서의 LLM 병렬 처리에 대한 가이드입니다.
- Making Deep Learning Go Brrrr From First Principles: LLM 루프라인 및 성능 엔지니어링에 대한 더 GPU 및 PyTorch 중심의 튜토리얼입니다.
- Cornell Understanding GPU Architecture site: GPU와 CPU 내부를 더 구체적으로 비교하는 이 책과 유사한 가이드입니다.
Appendix A: How does this change with GB200?
Blackwell은 전체 NVLink 대역폭의 2배(900GB/s)인 NVLink 5를 포함하여 많은 주요 네트워킹 변경 사항을 도입했습니다. B200은 H100과 마찬가지로 여전히 8-GPU 노드를 가지고 있지만, GB200 시스템(B200 GPU와 Grace CPU를 결합)은 훨씬 더 큰 NVLink 도메인(NVL72에서 72 GPU, 이론적으로 최대 576)을 도입합니다. 이 더 큰 NVLink 도메인은 또한 노드 송신 대역폭을 효과적으로 증가시켜 노드 수준 이상의 collective 비용을 줄입니다.

노드 내에서 이 증가된 대역폭(450GB/s에서 900GB/s로)은 각 GPU의 총 FLOPs/s도 두 배로 늘리기 때문에 큰 차이가 없습니다. NVLink의 대역폭이 훨씬 더 좋기 때문에 전문가 병렬 처리가 더 쉬워지지만 루프라인은 대부분 동일하게 유지됩니다.
노드를 넘어서면 상황이 더 많이 바뀝니다. 여기에서 가져온 SuperPod 다이어그램입니다.
보시다시피 노드당 송신 대역폭은 H100의 400GB/s에서 4 * 18 * 400 / 8 = 3.6TB/s로 증가합니다. FLOPs/chip도 두 배가 되기 때문에 유효한 노드 간 루프라인이 약 4배 향상됩니다. 이제 우리는 스케일 아웃 수준이 아니라 노드 수준에서 병목 현상이 발생하는지 걱정하기 시작할 수 있습니다.
Grace Hopper: NVIDIA는 또한 GH200 및 GB200 시스템을 판매하는데, 이는 일정 수의 GPU와 Grace CPU를 짝짓습니다. 예를 들어 GH200에는 1개의 H200과 1개의 Grace CPU가 있고, GB200 시스템에는 2개의 B200과 1개의 Grace CPU가 있습니다. 이 시스템의 장점은 CPU가 전체 대역폭 NVLink 연결(NVLink C2C라고 함)을 사용하여 GPU에 연결되므로 호스트 RAM으로 파라미터를 오프로드하는 데 유용한 매우 높은 CPU 대 GPU 대역폭을 갖는다는 것입니다. 즉, 주어진 GPU에 대해 호스트 메모리에 도달하는 대역폭은 다른 GPU의 HBM에 도달하는 것과 동일합니다.
Appendix B: More networking details
다음은 NVLink 4 스위치의 다이어그램입니다. 64개의 전체 NVLink4 포트(각각 2개의 물리적 레인 사용)가 있으며 레인 간 스위칭을 처리하는 대형 크로스바가 있습니다. 반면 TPU는 동적으로 재구성할 수 있는 거울이 있는 광 스위치를 사용합니다.

각 수준에서 우리는 사용 가능한 링크 대역폭 또는 총 스위치 대역폭에 의해 병목 현상이 발생할 수 있습니다.
- Node level: 노드 수준에서는 4 * 1.6TB/s = 6.4TB/s의 NVSwitch 대역폭이 있지만 8개의 각 GPU는 450GB/s만 스위치로 송신할 수 있으므로 실제로는 노드 내에서 450e9 * 8 = 3.6TB/s(전이중)의 피크 대역폭을 가집니다.
- SU/leaf level: SU 수준에서는 8개의 스위치가 1x400 Gbps Infiniband로 32개의 노드를 all-to-all 방식으로 연결합니다. 이는 노드로부터 8 * 32 * 400 / 8 = 12.8TB/s의 송신 대역폭을 제공하며, 스위치 수준에서 8 * 1.6TB/s = 12.8TB/s를 가지므로 둘 다 정확히 일치합니다.
- Spine level: spine 수준에서는 16개의 스위치가 2x400 Gbps 링크로 32개의 leaf 스위치를 연결하므로 32 * 16 * 400 * 2 / 8 = 51.2TB/s의 송신 대역폭을 가집니다. 16개의 스위치는 16 * 1.6TB/s = 25.6TB/s의 대역폭을 제공하므로 이 수준에서는 이것이 병목입니다.
GPU당 노드 수준에서 450GB/s의 GPU 대 GPU 대역폭, SU 수준에서 50GB/s, spine 수준에서 25 GB/s를 제공합니다.
GPU empirical AR bandwidth:
TPU v5p bandwidth (1 axis):

AllGather 대역폭도 여기 있습니다:


More on AllToAll costs:
여기서는 근사치 $\min(K / Z) * (Z - 1) / Z$를 실제 값 $(1 - ((Z - 1) / Z) ** K) * (Z - 1) / Z$와 비교할 수 있습니다. $Z$의 작은 값을 제외하고는 비슷합니다.
